Gated Recurrent Unit (GRU)
Gated Recurrent Unit (GRU)는 뉴욕대학교 조경현 교수가 제안한 방법입니다. 기존 LSTM이 너무 복잡한 모델이므로 좀 더 간단하면서 성능이 비슷한 방법을 제안하였습니다. 마찬가지로 GRU 또한 sigmoid σ로 구성 된 리셋(reset) 게이트(gate) rt와 업데이트(update) 게이트 zt가 있습니다. 마찬가지로 sigmoid 함수로 인해서 게이트의 출력값은 0과 1 사이가 나오므로, 데이터의 흐름을 게이트를 열고 닫아 제어할 수 있습니다. 기존 LSTM 대비 게이트의 숫자가 줄어든 것(4→2)을 볼 수 있고, 따라서 게이트에 딸려있던 파라미터들이 그만큼 줄어든 것 입니다.
rtztntht=σ(Wirxt+bir+Whrh(t−1)+bhr)=σ(Wizxt+biz+Whzh(t−1)+bhz)=tanh(Winxt+bin+rt(Whnh(t−1)+bhn))=(1−zt)nt+zth(t−1)
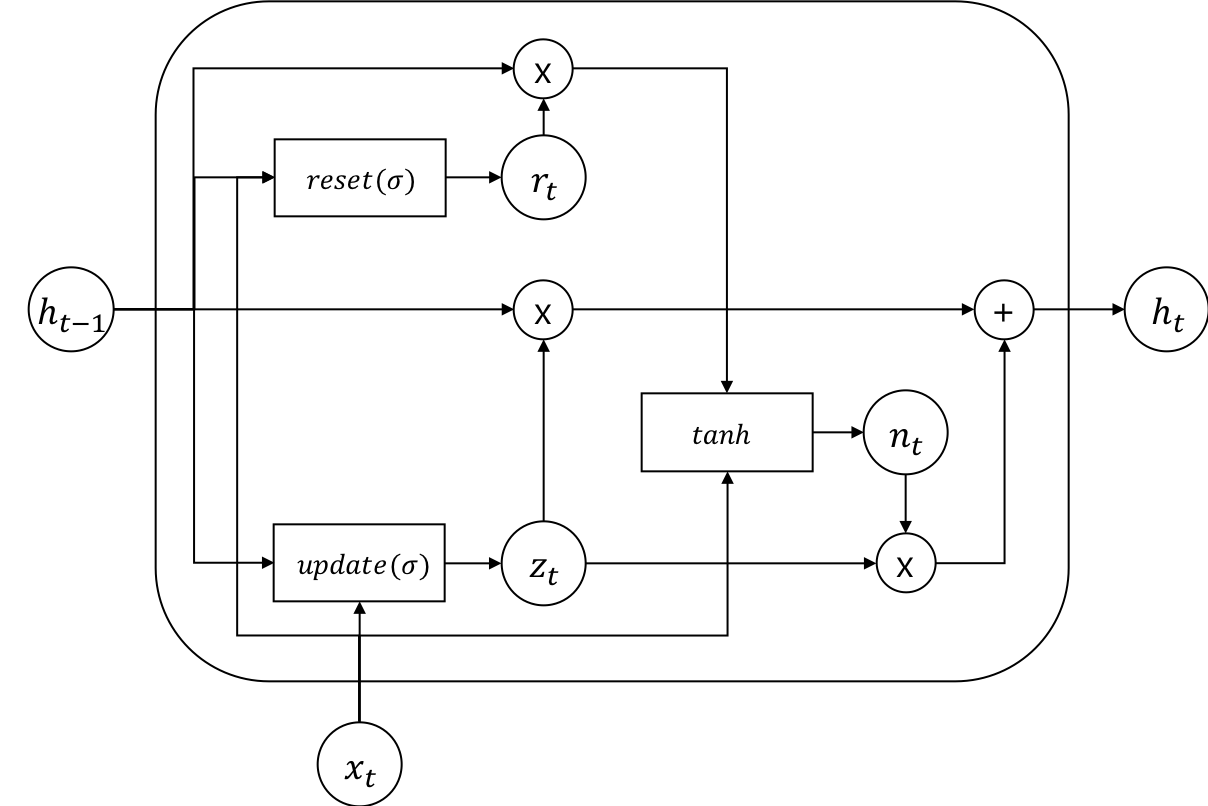
사실 LSTM 대비 GRU는 더 가벼운 몸집을 자랑하지만, 아직까지는 LSTM을 사용하는 빈도가 더 높은 것이 사실이긴 합니다. 사실 특별히 성능의 차이가 있다고 하기보단, LSTM과 GRU의 learning-rate나 hidden size등의 하이퍼 파라미터(hyper-parameter)가 다르므로 사용 모델에 따라서 다시 파라미터 셋팅을 연구 해야 하므로, 쉽게 이것저것 사용하기 힘든 부분도 있을 뿐더러, 연구자의 취향에 가까운 것 같습니다.