Google Neural Machine Translation (GNMT)
(Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation)
Google은 2016년 논문([Wo at el.2016] )을 발표하여 그들의 번역시스템에 대해서 상세히 소개하였습니다. 실제 시스템에 적용된 모델 구조(architecture)부터 훈련 방법까지 상세히 기술하였기 때문에, 실제 번역 시스템을 구성하고자 할 때에 좋은 참고자료(reference)가 될 수 있습니다. 또한 다른 논문들에서 실험 결과에 대해 설명할 때, GNMT를 baseline으로 참조하기도 합니다. 아래의 내용들은 그들의 논문에서 소개한 내용을 다루도록 하겠습니다.
Model Architecture
Google도 seq2seq 기반의 모델을 구성하였습니다. 다만, 구글은 훨씬 방대한 데이터셋을 가지고 있기 때문에 그에 맞는 깊은 모델을 구성하였습니다. 따라서 아래에 소개될 방법들이 깊은 모델들을 효율적으로 훈련 할 수 있도록 사용되었습니다.
Residual Connection

보통 LSTM layer를 4개 이상 쌓기 시작하면 모델이 더욱 깊어(deeper)짐에 따라서 성능 효율이 저하되기 시작합니다. 따라서 Google은 깊은 모델은 효율적으로 훈련시키기 위하여 residual connection을 적용하였습니다.
Bi-directional Encoder for First Layer
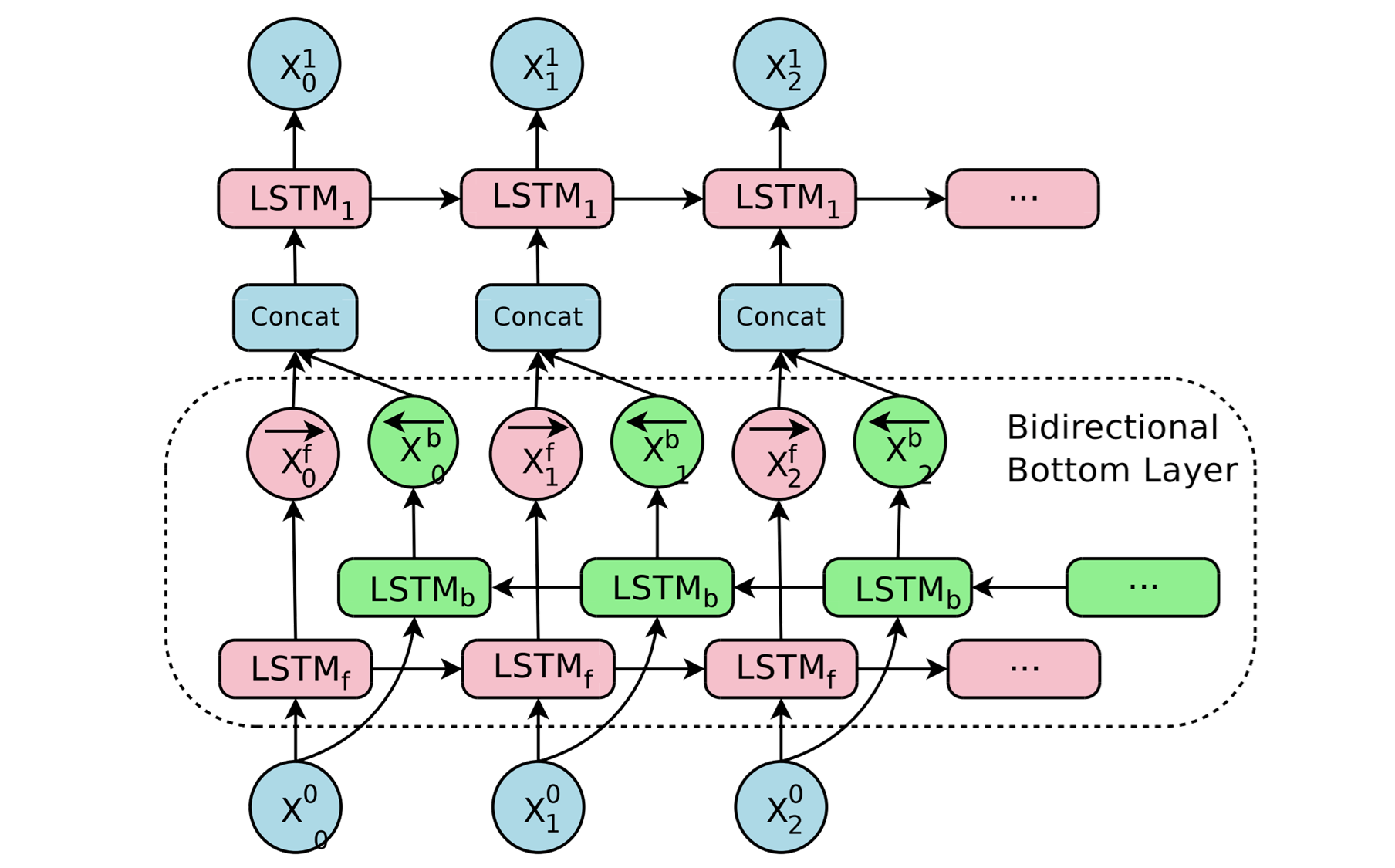
또한, 모든 LSTM stack에 대해서 bi-directional LSTM을 적용하는 대신에, 첫번째 층에 대해서만 bi-directional LSTM을 적용하였습니다. 따라서 훈련(training) 및 추론(inference) 속도에 개선이 있었습니다.
Segmentation Approachs
Wordpiece Model
구글도 마찬가지로 BPE 모델을 사용하여 tokenization을 수행하였습니다. 그리고 그들은 그들의 tokenizer를 오픈소스로 공개하였습니다. -- SentencePiece: https://github.com/google/sentencepiece 마찬가지로 아래와 같이 띄어쓰기는 underscore로 치환하고, 단어를 subword별로 통계에 따라 segmentation 합니다.
- original: Jet makers feud over seat width with big orders at stake
- wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
Training Criteria

Google은 강화학습을 다룬 챕터에서 설명한 강화학습 기법을 사용하여 Maximum Likelihood Estimation (MLE)방식의 훈련된 모델에 fine-tuning을 수행하였습니다. 따라서 위의 테이블과 같은 추가적이 성능 개선을 얻어낼 수 있었습니다.
기존 MLE 방식의 목적함수(objective)를 아래와 같이 구성합니다. 은 최적(optimal)의 정답 데이터를 의미합니다.
여기에 추가로 RL방식의 목적함수(objective)를 추가하였는데 이 방식이 policy gradient 방식과 같습니다.
위의 수식도 Minimum Risk Training (MRT) 방식과 비슷합니다. 또한 정답과 sampling 데이터 사이의 유사도(점수)를 의미합니다. 가장 큰 차이점은 기존에는 risk로 취급하여 최소화(minimize)하는 방향으로 훈련하였지만, 이번에는 reward로 취급하여 최대화(maximize)하는 방향으로 훈련하게 된다는 것 입니다.
이렇게 새롭게 추가된 목적함수(objective)를 아래와 같이 기존의 MLE방식의 목적함수와 선형 결합(linear combination)을 취하여 최종적인 목적함수가 완성됩니다.
이때에 값은 주로 0.017로 셋팅하였습니다. 위와 같은 방법의 성능을 실험한 결과는 다음과 같습니다.
의 경우에는 성능이 약간 하락함을 보였습니다. 하지만 이는 decoder의 length penalty, coverage penalty와 결합되었기 때문이고, 이 페널티(panalty)들이 없을 때에는 훨씬 큰 성능 향상이 있었다고 합니다.
Quantization
실제 인공신경망을 사용한 제품을 개발할 때에는 여러가지 어려움에 부딪히게 됩니다. 이때, Quantization을 도입함으로써 아래와 같은 여러가지 이점을 얻을 수 있습니다.
- 계산량을 줄여 자원의 효율적 사용과 응답시간의 감소를 얻을 수 있다.
- 모델의 실제 저장되는 크기를 줄여 deploy를 효율적으로 할 수 있다.
- 부가적으로 regularization의 효과를 볼 수 있다.

위의 그래프를 보면 전체적으로 Quantized verion이 더 낮은 loss를 보여주는 것을 확인할 수 있습니다.
Search
Length Penalty and Coverage Penalty
Google은 기존에 소개한 Length Penalty에 추가로 Coverage Penalty를 사용하여 좀 더 성능을 끌어올렸습니다. Coverage penalty는 attention weight(probability)의 값의 분포에 따라서 매겨집니다. 이 페널티는 좀 더 attention이 고루 잘 퍼지게 하기 위함입니다.
Coverage penalty의 수식을 들여다보면, 각 source word 별로 attention weight의 합을 구하고, 그것의 평균(=합)을 내는 것을 볼 수 있습니다. 로그(log)를 취했기 때문에 그 중에 attention weight가 편중되어 있다면, 편중되지 않은 source word는 매우 작은 음수 값을 가질 것이기 때문에 좋은 점수를 받을 수 없을 겁니다.
실험에 의하면 와 는 각각 정도가 좋은것으로 밝혀졌습니다. 하지만, 상기한 강화학습 방식을 training criteria에 함께 이용하면 그다지 그 값은 중요하지 않다고 하였습니다.
Training Procedure

Google은 stochastic gradient descent (SGD)를 써서 훈련 시키는 것 보다, Adam과 섞어 사용하면 (epoch 1까지 Adam) 더 좋은 성능을 발휘하는 것을 확인하였습니다.
Evaluation
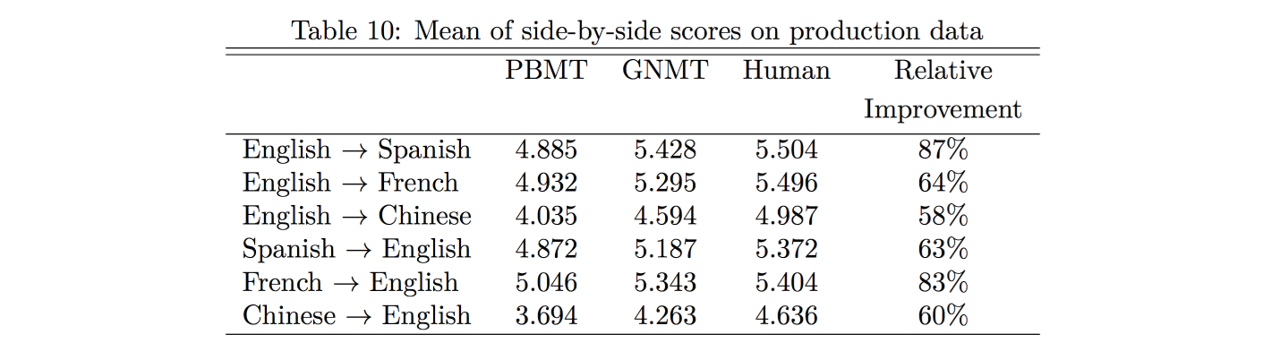
실제 번역 품질을 측정하기 위하여 BLEU 이외에도 정성평가(implicit human evaluation)을 통하여 GNMT의 성능 개선의 정도를 측정하였습니다. 0(Poor)에서 6(Perfect)점 사이로 점수를 매겨 사람의 번역 결과 점수를 최대치로 가정하고 성능의 개선폭을 계산하였습니다. 실제 SMT 방식 대비 엄청난 천지개벽 수준의 성능 개선이 이루어진 것을 알 수 있고, 일부 언어쌍에 대해서는 거의 사람의 수준에 필적하는 성능을 보여주는 것을 알 수 있습니다.