Sequence to Sequence
Architecture Overview
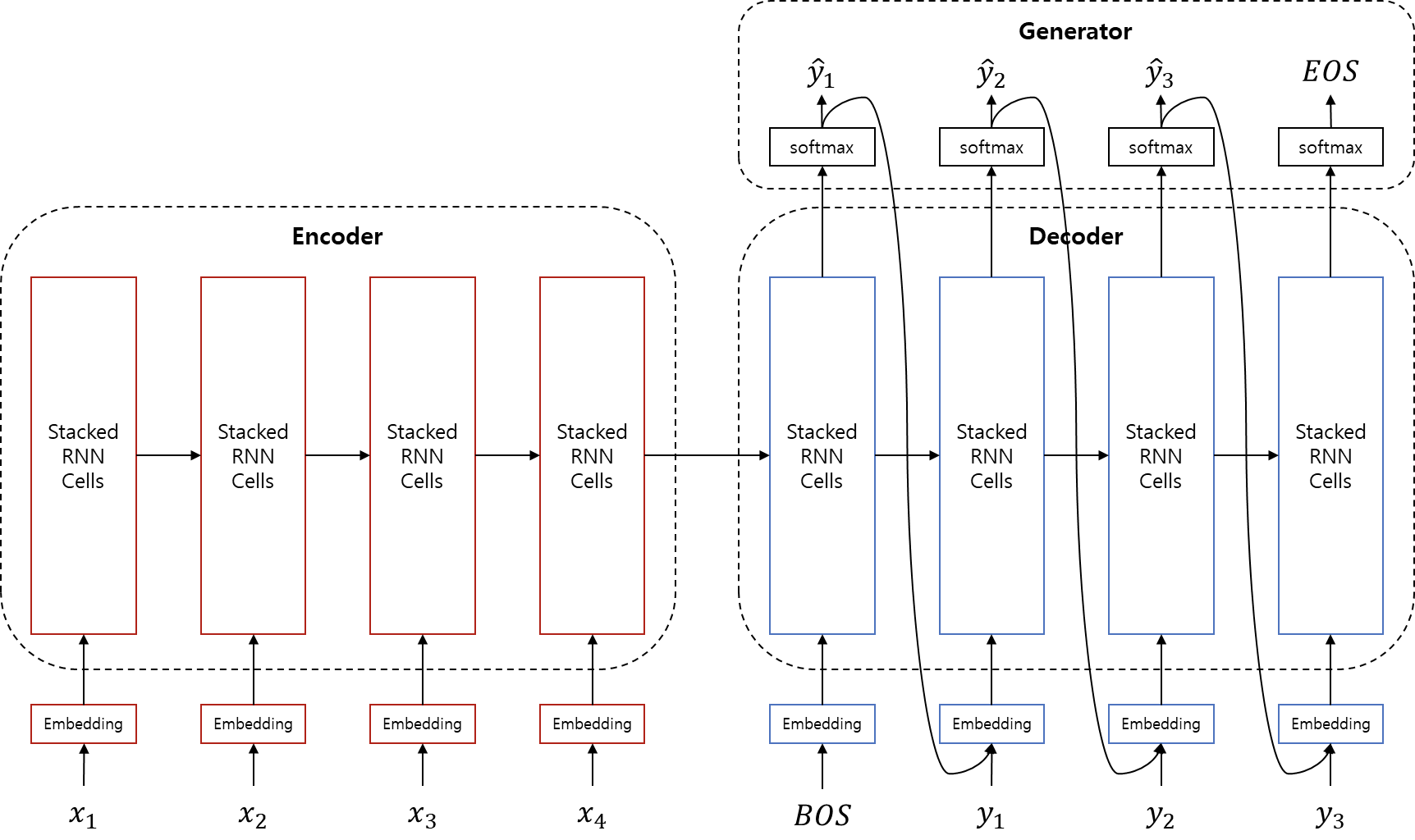
먼저 번역 또는 seq2seq 모델을 이용한 작업을 간단하게 수식화 해보겠습니다.
를 최대로 하는 모델 파라미터()를 Maximum Likelihood Estimation(MLE)를 통해 찾아야 합니다. 즉, 모델 파라미터가 주어졌을 때, source 문장 를 받아서 target 문장 를 반환할 확률을 최대로 하는 모델 파라미터를 학습하는 것 입니다. 이를 위해서 seq2seq는 크게 3개 서브 모듈(encoder, decoder, generator)로 구성되어 있습니다.
Encoder
인코더는 source 문장을 입력으로 받아 문장을 함축하는 의미의 vector로 만들어 냅니다. 를 모델링 하는 것이라고 볼 수 있습니다. 사실 새로운 형태라기 보단, 이전 챕터에서 다루었던 텍스트 분류(Text Classificaion)에서 사용되었던 RNN 모델과 거의 같다고 볼 수 있습니다. 를 모델링하여, 주어진 문장을 벡터화(vectorize)하여 해당 도메인의 hyper-plane의 어떤 한 점에 projection 시키는 작업이라고 할 수 있습니다.
다만, 기존의 text classification에서는 모든 정보가 필요하지 않기 때문에 (예를들어 감성분석(Sentiment Analysis)에서는 '나는'과 같이 중립적인 단어는 감성을 분류하는데 필요하지 않기 때문에 해당 정보를 굳이 간직해야 하지 않을 수도 있습니다.) vector로 만들어내는 과정인 정보를 압축함에 있어서 손실 압축을 해도 되는 task이지만, 기계번역에 있어서는 이상적으로는 거의 무손실 압축을 해내야 하는 차이는 있습니다.
Encoder를 수식으로 나타내면 위와 같습니다. 는 concatenate를 의미합니다. 위의 수식은 time-step별로 GRU를 통과시킨 것을 나타낸 것이고, 사실상 실제 코딩을 하게 되면 아래와 같이 됩니다.
Decoder
마찬가지로 디코더도 사실 새로운 개념이 아닙니다. 이전 챕터에서 다루었던 신경망언어모델(Nerual Network Langauge Model, NNLM)의 연장선으로써, 조건부 신경망언어모델(Conditional Neural Network Language Model)이라고 할 수 있습니다. 위에서 다루었던 seq2seq모델의 수식을 좀 더 time-step에 대해서 풀어서 써보면 아래와 같습니다.
보면 RNNLM의 수식에서 조건부에 가 추가 된 것을 확인 할 수 있습니다. 즉, 이제까지 번역 한 (이전 time-step의) 단어들과 encoder의 결과에 기반해서 현재 time-step의 단어를 유추해 내는 작업을 수행합니다.
위의 수식은 decoder를 나타낸 것입니다. 특기할 점은 decoder 입력의 초기값으로써, 에 BOS를 넣어준다는 것 입니다.
Generator
이 모듈은 아래와 같이 Decoder에서 vector를 받아 softmax를 계산하여 최고 확률을 가진 단어를 선택하는 단순한 작업을 하는 모듈 입니다. 일때, 은 EOS 토큰이 됩니다. 주의할 점은 이 마지막 은 decoder 계산의 종료를 나타내기 때문에, 이론상으로는 decoder의 입력으로 들어가는 일이 없습니다.
Applications of seq2seq
이와 같이 구성된 Seq2seq 모델은 꼭 기계번역의 task에서만 사용해야 하는 것이 아니라 정말 많은 분야에 적용할 수 있습니다. 특정 도메인의 sequential한 입력을 다른 도메인의 sequential한 데이터로 출력하는데 탁월한 능력을 발휘합니다.
| Seq2seq Applications | Task (From-To) |
|---|---|
| Neural Machine Translation (NMT) | 특정 언어 문장을 입력으로 받아 다른 언어의 문장으로 출력 |
| Chatbot | 사용자의 문장 입력을 받아 대답을 출력 |
| Summarization | 긴 문장을 입력으로 받아 같은 언어의 요약된 문장으로 출력 |
| Other NLP Task | 사용자의 문장 입력을 받아 프로그래밍 코드로 출력 등 |
| Automatic Speech Recognition (ASR) | 사용자의 음성을 입력으로 받아 해당 언어의 문자열(문장)으로 출력 |
| Lip Reading | 입술 움직임의 동영상을 입력으로 받아 해당 언어의 문장으로 출력 |
| Image Captioning | 변형된 seq2seq를 사용하여 이미지를 입력으로 받아 그림을 설명하는 문장을 출력 |
Limitation
사실 seq2seq는 AutoEncoder와 굉장히 역할이 비슷하다고 볼 수 있습니다. 그 중에서도 특히 Sequential한 데이터에 대한 task에 강점이 있는 모델이라고 볼 수 있습니다. 하지만 아래와 같은 한계점들이 있습니다.
Memorization
Neural Network 모델은 데이터를 압축하는데에 탁월한 성능(Manifold Assumption 참고)을 지녔습니다. 하지만, Neural Network은 도라에몽의 주머니처럼 무한하게 정보를 집어넣을 수 없습니다. 따라서 표현할 수 있는 정보는 한계가 있기 때문에, 문장(또는 sequence)가 길어질수록 기억력이 떨어지게 됩니다. 비록 LSTM이나 GRU를 사용함으로써 성능을 끌어올릴 수 있지만, 한계가 있기 마련입니다.
Lack of Structural Information
현재 주류의 Deeplearning NLP는 문장을 이해함에 있어서 구조 정보를 사용하기보단, 단순히 sequential한 데이터로써 다루는 경향이 있습니다. 비록 이러한 접근방법은 현재까지 대성공을 거두고 있지만, 다음 단계로 나아가기 위해서는 구조 정보도 필요할 것이라 생각하는 사람들이 많습니다.
Chatbot?
사실 이 항목은 단점이라기보다는 그냥 당연한 이야기일 수 있습니다. seq2seq는 sequential한 데이터를 입력으로 받아서 다른 도메인의 sequential한 데이터로 출력하는 능력이 뛰어납니다. 따라서, 처음에는 많은 사람들이 seq2seq를 잘 훈련시키면 Chatbot의 기능도 어느정도 할 수 있지 않을까 하는 기대를 했습니다. 하지만 자세히 생각해보면, 대화의 흐름에서 대답은 질문에 비해서 새로운 정보(지식-knowledge, 문맥-context)가 추가 된 경우가 많습니다. 따라서 기존의 typical한 seq2seq의 task(번역, 요약)등은 새로운 정보의 추가가 없기 때문에 잘 해결할 수 있었지만, 대화의 경우에는 좀 더 발전된 architecture가 필요할 것 입니다.
Code
NMT를 목표로하는 seq2seq를 PyTorch로 구현하는 방법을 소개합니다. 이번 챕터에서 사용될 전체 코드는 저자의 깃허브에서 다운로드 할 수 있습니다. (업데이트 여부에 따라 코드가 약간 다를 수 있습니다.)
- github repo url: https://github.com/kh-kim/simple-nmt
Encoder
class Encoder(nn.Module):
def __init__(self, word_vec_dim, hidden_size, n_layers = 4, dropout_p = .2):
super(Encoder, self).__init__()
self.rnn = nn.LSTM(word_vec_dim, int(hidden_size / 2), num_layers = n_layers, dropout = dropout_p, bidirectional = True, batch_first = True)
def forward(self, emb):
# |emb| = (batch_size, length, word_vec_dim)
if isinstance(emb, tuple):
x, lengths = emb
x = pack(x, lengths.tolist(), batch_first = True)
else:
x = emb
y, h = self.rnn(x)
# |y| = (batch_size, length, hidden_size)
# |h[0]| = (num_layers * 2, batch_size, hidden_size / 2)
if isinstance(emb, tuple):
y, _ = unpack(y, batch_first = True)
return y, h
Decoder
class Decoder(nn.Module):
def __init__(self, word_vec_dim, hidden_size, n_layers = 4, dropout_p = .2):
super(Decoder, self).__init__()
self.rnn = nn.LSTM(word_vec_dim + hidden_size, hidden_size, num_layers = n_layers, dropout = dropout_p, bidirectional = False, batch_first = True)
def forward(self, emb_t, h_t_1_tilde, h_t_1):
# |emb_t| = (batch_size, 1, word_vec_dim)
# |h_t_1_tilde| = (batch_size, 1, hidden_size)
# |h_t_1[0]| = (n_layers, batch_size, hidden_size)
batch_size = emb_t.size(0)
hidden_size = h_t_1[0].size(-1)
if h_t_1_tilde is None:
h_t_1_tilde = emb_t.new(batch_size, 1, hidden_size).zero_()
x = torch.cat([emb_t, h_t_1_tilde], dim = -1)
y, h = self.rnn(x, h_t_1)
return y, h
Generator
class Generator(nn.Module):
def __init__(self, hidden_size, output_size):
super(Generator, self).__init__()
self.output = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim = -1)
def forward(self, x):
# |x| = (batch_size, length, hidden_size)
y = self.softmax(self.output(x))
# |y| = (batch_size, length, output_size)
return y
Sequence-to-Sequence (Combine)
class Seq2Seq(nn.Module):
def __init__(self, input_size, word_vec_dim, hidden_size, output_size, n_layers = 4, dropout_p = .2):
self.input_size = input_size
self.word_vec_dim = word_vec_dim
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
super(Seq2Seq, self).__init__()
self.emb_src = nn.Embedding(input_size, word_vec_dim)
self.emb_dec = nn.Embedding(output_size, word_vec_dim)
self.encoder = Encoder(word_vec_dim, hidden_size, n_layers = n_layers, dropout_p = dropout_p)
self.decoder = Decoder(word_vec_dim, hidden_size, n_layers = n_layers, dropout_p = dropout_p)
self.attn = Attention(hidden_size)
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.tanh = nn.Tanh()
self.generator = Generator(hidden_size, output_size)
def generate_mask(self, x, length):
mask = []
max_length = max(length)
for l in length:
if max_length - l > 0:
mask += [torch.cat([x.new_ones(1, l).zero_(), x.new_ones(1, (max_length - l))], dim = -1)]
else:
mask += [x.new_ones(1, l).zero_()]
mask = torch.cat(mask, dim = 0).byte()
return mask
def merge_encoder_hiddens(self, encoder_hiddens):
new_hiddens = []
new_cells = []
hiddens, cells = encoder_hiddens
for i in range(0, hiddens.size(0), 2):
new_hiddens += [torch.cat([hiddens[i], hiddens[i + 1]], dim = -1)]
new_cells += [torch.cat([cells[i], cells[i + 1]], dim = -1)]
new_hiddens, new_cells = torch.stack(new_hiddens), torch.stack(new_cells)
return (new_hiddens, new_cells)
def forward(self, src, tgt):
batch_size = tgt.size(0)
mask = None
x_length = None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
# |mask| = (batch_size, length)
else:
x = src
if isinstance(tgt, tuple):
tgt = tgt[0]
emb_src = self.emb_src(x)
# |emb_src| = (batch_size, length, word_vec_dim)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
# |h_src| = (batch_size, length, hidden_size)
# |h_0_tgt| = (n_layers * 2, batch_size, hidden_size / 2)
# merge bidirectional to uni-directional
h_0_tgt, c_0_tgt = h_0_tgt
h_0_tgt = h_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
c_0_tgt = c_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
# |h_src| = (batch_size, length, hidden_size)
# |h_0_tgt| = (n_layers, batch_size, hidden_size)
h_0_tgt = (h_0_tgt, c_0_tgt)
emb_tgt = self.emb_dec(tgt)
# |emb_tgt| = (batch_size, length, word_vec_dim)
h_tilde = []
h_t_tilde = None
decoder_hidden = h_0_tgt
for t in range(tgt.size(1)):
emb_t = emb_tgt[:, t, :].unsqueeze(1)
# |emb_t| = (batch_size, 1, word_vec_dim)
# |h_t_tilde| = (batch_size, 1, hidden_size)
decoder_output, decoder_hidden = self.decoder(emb_t, h_t_tilde, decoder_hidden)
# |decoder_output| = (batch_size, 1, hidden_size)
# |decoder_hidden| = (n_layers, batch_size, hidden_size)
context_vector = self.attn(h_src, decoder_output, mask)
# |context_vector| = (batch_size, 1, hidden_size)
h_t_tilde = self.tanh(self.concat(torch.cat([decoder_output, context_vector], dim = -1)))
# |h_t_tilde| = (batch_size, 1, hidden_size)
h_tilde += [h_t_tilde]
h_tilde = torch.cat(h_tilde, dim = 1)
# |h_tilde| = (batch_size, length, hidden_size)
y_hat = self.generator(h_tilde)
# |y_hat| = (batch_size, length, output_size)
return y_hat
Loss function
seq2seq는 기본적으로 각 time-step 별로 가장 확률이 높은 단어를 선택하는 분류 작업(classification task)이므로, cross entropy를 손실함수(loss function)으로 사용합니다. 또한 기본적으로 조건부 언어모델(conditional language model)이라고 볼 수 있기 때문에, 이전 언어모델 챕터에서 다루었듯이 perplexity를 통해 번역 모델의 성능을 나타낼 수 있고, 이 또한 (cross) entropy와 매우 깊은 연관을 가집니다.
아래는 손실(loss)값을 계산하기 위해 PyTorch로부터 손실함수를 준비하는 모습입니다. 사실, 실제 구현할 때에는 softmax layer + cross entropy를 사용하기보단, log softmax layer + negative log likelihood를 사용합니다.
loss_weight = torch.ones(output_size)
loss_weight[data_loader.PAD] = 0
criterion = nn.NLLLoss(weight = loss_weight, size_average = False)
아래와 같이 cross entropy 수식은 실제 정답의 확률과 feed-forward를 통해 얻은 신경망()의 해당 로그(log)확률 값을 곱하여 평균을 구합니다. 사실 의 값은 이므로 수식에서 생략할 수 있습니다.
따라서 softmax layer 대신, log softmax layer를 사용하여 로그 확률을 구하고, 수식의 나머지 작업을 수행하면 됩니다.
def get_loss(y, y_hat, criterion, do_backward = True):
# |y| = (batch_size, length)
# |y_hat| = (batch_size, length, output_size)
batch_size = y.size(0)
loss = criterion(y_hat.contiguous().view(-1, y_hat.size(-1)), y.contiguous().view(-1))
if do_backward:
loss.div(batch_size).backward()
return loss