Input Feeding
Overview
Decoder output과 Attention 결과값을 concatenate한 이후에 Generator 모듈에서 softmax를 취하여 을 구합니다. 하지만 이러한 softmax 과정에서 많은 정보(예를 들어 attention 정보 등)가 손실됩니다. 따라서 단순히 다음 time-step에 을 feeding 하는 것보다, concatenation layer의 출력도 같이 feeding 해주면 정보의 손실 없이 더 좋은 효과를 얻을 수 있습니다.
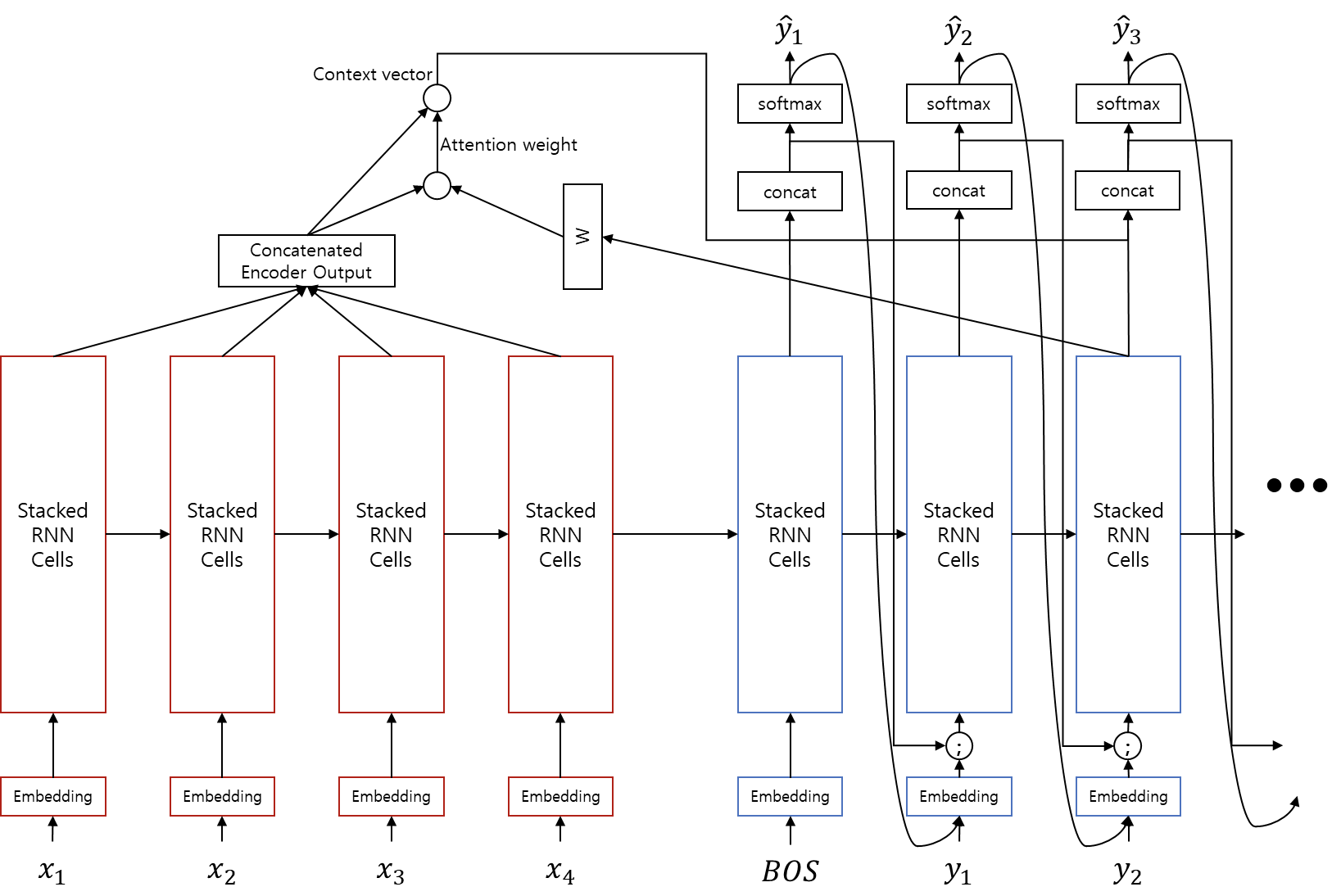
와 달리 concatenation layer의 출력은 가 embedding layer에서 dense vector(=embedding vector)로 변환되고 난 이후에 embedding vector와 concatenate되어 decoder RNN에 입력으로 주어지게 됩니다. 이러한 과정을 input feeding이라고 합니다.
위의 수식은 attention과 input feeding이 추가된 seq2seq의 처음부터 끝까지 입니다. 는 이제 를 입력으로 받기 때문에, 모든 time-step을 한번에 처리하도록 구현할 수 없다는 점이 구현상의 차이점입니다.
Disadvantage
이 방식은 훈련 속도 저하라는 단점을 가집니다. input feeding이전 방식에서는 훈련 할 때에는 teacher forcing 방식이기 때문에(모든 입력을 알고 있기 때문에), encoder와 마찬가지로 decoder도 모든 time-step에 대해서 한번에 feed-forward 작업이 가능했습니다. 하지만 input feeding으로 인해, decoder RNN의 input으로 이전 time-step의 결과가 필요하게 되어, 다시 추론(inference)할 때 처럼 auto-regressive 속성으로 인해 각 time-step 별로 순차적으로 계산을 해야 합니다.
하지만 이 단점이 크게 부각되지 않는 이유는 어차피 추론(inference)단계에서는 decoder는 input feeding이 아니더라도 time-step 별로 순차적으로 계산되어야 하기 때문입니다. 추론 단계에서는 이전 time-step의 output인 를 decoder(정확하게는 decoder 이전의 embedding layer)의 입력으로 사용해야 하기 때문에, 어쩔 수 없이 병렬처리가 아닌 순차적으로 계산해야 합니다. 따라서 추론 할 때, input feeding으로 인한 속도 저하는 거의 없습니다.
Evaluation
| NMT system | Perplexity | BLEU |
|---|---|---|
| Base | 10.6 | 11.3 |
| Base + reverse | 9.9 | 12.6(+1.3) |
| Base + reverse + dropout | 8.1 | 14.0(+1.4) |
| Base + reverse + dropout + attention | 7.3 | 16.8(+2.8) |
| Base + reverse + dropout + attention + feed input | 6.4 | 18.1(+1.3) |
WMT’14 English-German results Perplexity(PPL) and BLEU [Loung, arXiv 2015]
현재 방식을 처음 제안한 [Loung et al.2015] Effective Approaches to Attention-based Neural Machine Translation에서는 실험 결과를 위와 같이 주장하였습니다. 실험 대상은 아래와 같습니다.
- Baseline: 기본적인 seq2seq 모델
- Reverse: Bi-directional LSTM을 encoder에 적용
- Dropout: probability 0.2
- Global Attention
- Input Feeding
우리는 이 실험에서 attention과 input feeding을 사용함으로써, 훨씬 더 나은 성능을 얻을 수 있음을 알 수 있습니다.
Code
class Seq2Seq(nn.Module):
def __init__(self, input_size, word_vec_dim, hidden_size, output_size, n_layers = 4, dropout_p = .2):
self.input_size = input_size
self.word_vec_dim = word_vec_dim
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
super(Seq2Seq, self).__init__()
self.emb_src = nn.Embedding(input_size, word_vec_dim)
self.emb_dec = nn.Embedding(output_size, word_vec_dim)
self.encoder = Encoder(word_vec_dim, hidden_size, n_layers = n_layers, dropout_p = dropout_p)
self.decoder = Decoder(word_vec_dim, hidden_size, n_layers = n_layers, dropout_p = dropout_p)
self.attn = Attention(hidden_size)
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.tanh = nn.Tanh()
self.generator = Generator(hidden_size, output_size)
def generate_mask(self, x, length):
mask = []
max_length = max(length)
for l in length:
if max_length - l > 0:
mask += [torch.cat([x.new_ones(1, l).zero_(), x.new_ones(1, (max_length - l))], dim = -1)]
else:
mask += [x.new_ones(1, l).zero_()]
mask = torch.cat(mask, dim = 0).byte()
return mask
def forward(self, src, tgt):
batch_size = tgt.size(0)
mask = None
x_length = None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
# |mask| = (batch_size, length)
else:
x = src
if isinstance(tgt, tuple):
tgt = tgt[0]
emb_src = self.emb_src(x)
# |emb_src| = (batch_size, length, word_vec_dim)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
# |h_src| = (batch_size, length, hidden_size)
# |h_0_tgt| = (n_layers * 2, batch_size, hidden_size / 2)
# merge bidirectional to uni-directional
h_0_tgt, c_0_tgt = h_0_tgt
h_0_tgt = h_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
c_0_tgt = c_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
# |h_src| = (batch_size, length, hidden_size)
# |h_0_tgt| = (n_layers, batch_size, hidden_size)
h_0_tgt = (h_0_tgt, c_0_tgt)
emb_tgt = self.emb_dec(tgt)
# |emb_tgt| = (batch_size, length, word_vec_dim)
h_tilde = []
h_t_tilde = None
decoder_hidden = h_0_tgt
for t in range(tgt.size(1)):
emb_t = emb_tgt[:, t, :].unsqueeze(1)
# |emb_t| = (batch_size, 1, word_vec_dim)
# |h_t_tilde| = (batch_size, 1, hidden_size)
decoder_output, decoder_hidden = self.decoder(emb_t, h_t_tilde, decoder_hidden)
# |decoder_output| = (batch_size, 1, hidden_size)
# |decoder_hidden| = (n_layers, batch_size, hidden_size)
context_vector = self.attn(h_src, decoder_output, mask)
# |context_vector| = (batch_size, 1, hidden_size)
h_t_tilde = self.tanh(self.concat(torch.cat([decoder_output, context_vector], dim = -1)))
# |h_t_tilde| = (batch_size, 1, hidden_size)
h_tilde += [h_t_tilde]
h_tilde = torch.cat(h_tilde, dim = 1)
# |h_tilde| = (batch_size, length, hidden_size)
y_hat = self.generator(h_tilde)
# |y_hat| = (batch_size, length, output_size)
return y_hat