Reinforcement Learning for Natural Language Processing
Discriminative learning vs Generative learning
2012년 이미지넷 대회(ImageNet competition)에서 딥러닝을 활용한 AlexNet이 우승을 차지한 이래로 컴퓨터 비전(Computer Vision), 음성인식(Speech Recognition), 자연어처리(Natural Language Processing) 등이 차례로 딥러닝에 의해 정복당해 왔습니다. 딥러닝이 뛰어난 능력을 보인 분야는 특히 분류(classification) 분야였습니다. 기존의 전통적인 방식과 달리 패턴 인식(pattern recognition) 분야에서는 압도적인 성능을 보여주었습니다. 이러한 분류(classification) 문제는 보통 Discriminative Learning에 속하는데 이를 일반화 하면 다음과 같습니다.
주어진 에 대해서 최대의 값을 갖도록 하는 파라미터 를 찾아내는 것 입니다. 이러한 조건부 확률 분포를 학습하는 것을 discriminative learning이라고 부릅니다. 하지만 이에 반해 Generative Learning은 확률분포 를 학습하는 것을 이릅니다. 따라서 Generative learning이 훨씬 더 학습하기 어렵습니다. 예를 들어
- 사람의 생김새()가 주어졌을 때 성별()의 확률 분포를 배우는 것
- 사람의 생김새()와 성별() 자체의 확률 분포를 배우는 것
두가지 경우를 비교하면 2번째가 훨씬 더 어려움을 알 수 있습니다. Discriminative learning은 와 와의 관계를 배우는 것이지만, generative learning은 자체를 배우는 것이기 때문입니다. 그리고 이것을 수식으로 일반화 하면 아래와 같습니다.
사실 이제는 패턴인식과 같은 discriminative learning은 이제 딥러닝으로 너무나도 당연하게 잘 해결되기 때문에, 사람들의 관심과 연구 트렌드는 위와 같은 generative learning으로 집중되고 있습니다.
Generative Adversarial Network (GAN)
2016년부터 주목받기 시작하여 2017년에 가장 큰 화제였던 분야는 단연 GAN이라고 말할 수 있습니다. Variational Auto Encoder(VAE)와 함께 Generative learning을 대표하는 방법 중에 하나입니다. GAN을 통해서 우리는 사실같은 이미지를 생성해내고 합성해내는 일들을 딥러닝을 통해 할 수 있게 되었습니다. 이러한 합성/생성 된 이미지들을 통해, 자율주행과 같은 실생활에 중요하고 어렵지만 훈련 데이터셋을 얻기 힘든 문제들을 해결 하는데 큰 도움을 얻을 수 있으리라고 예상 됩니다. (실제로 GTA게임을 통해 자율주행을 훈련하려는 시도는 이미 유명합니다.)
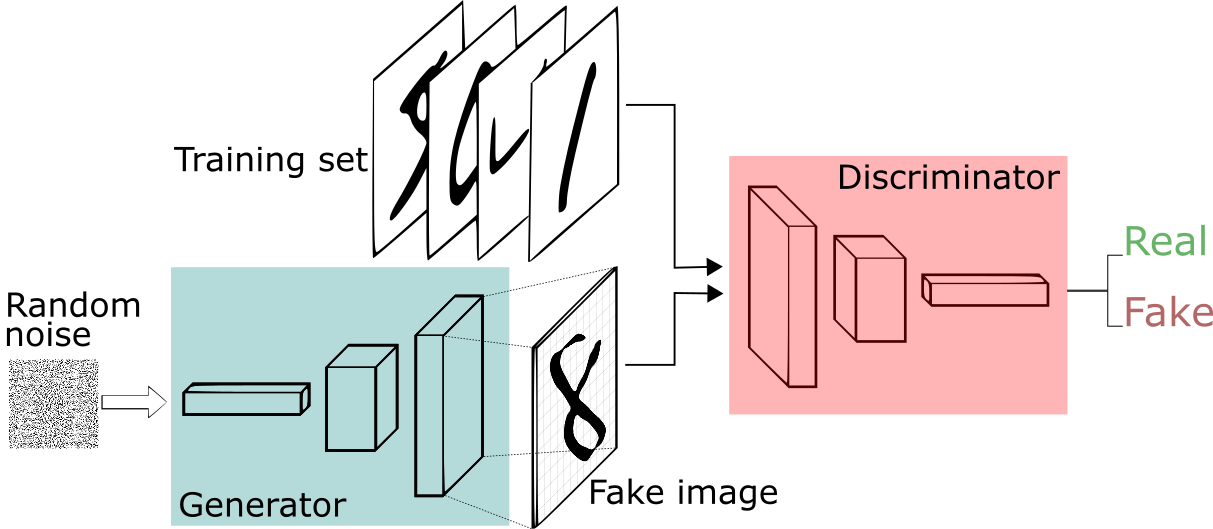 Generative Adversarial Network overview - Image from web
Generative Adversarial Network overview - Image from web
위와 같이 Generator()와 Discriminator() 2개의 모델을 각기 다른 목표를 가지고 동시에 훈련시키는 것입니다. 는 임의의 이미지를 입력으로 받아 이것이 실제 존재하는 이미지인지, 아니면 합성된 이미지인지 탐지 해 내는 역할을 합니다. 는 어떤 이미지를 생성 해 내되, 를 속이는 이미지를 만들어 내는 것이 목표입니다. 이렇게 두 모델이 잘 균형을 이루며 min/max 게임을 펼치게 되면, 는 결국 훌륭한 이미지를 합성 해 내는 Generator가 됩니다.
Why GAN is important?
마찬가지의 이유로 GAN또한 주목받게 됩니다. 예를 들어, 생성된 이미지와 정답 이미지 간의 차이를 비교하는데 MSE(Mean Square Error)방식을 사용하게 되면, 결국 이미지는 MSE를 최소화 하기 위해서 자신의 학습했던 확률 분포의 중간으로 출력을 낼 수 밖에 없습니다. 예를 들어 사람의 얼굴을 일부 가리고 가려진 부분을 채워 넣도록 훈련한다면, MSE 손실함수(loss function) 아래에서는 각 픽셀마다 가능한 확률 분포의 평균값으로 채워 질 겁니다. 이것이 MSE를 최소화 하는 길이기 때문입니다. 하지만 우리는 그런 흐리멍텅한 이미지를 잘 생성된(채워진) 이미지라고 하지 않습니다. 따라서 사실적인 표현을 위해서는 MSE보다 정교한 목적함수(objective function)를 쓸 수 밖에 없습니다. GAN에서는 그러한 복잡한 함수를 가 근사하여 해결한 것 입니다.
GAN과 NLP
위와 같이 GAN은 컴퓨터 비전(CV)분야에서 대성공을 이루었지만 자연어처리(NLP)에서는 적용이 어려웠습니다. 그 이유는 Natural Language 자체의 특성에 있습니다. 이미지라는 것은 어떠한 continuous한 값들로 채워진 2차원의 matrix입니다. 하지만 이와 달리 단어라는 것은 discrete한 symbol로써, 결국 언어라는 것은 어떠한 descrete한 값들의 순차적인 배열 입니다. 비록 우리는 NNLM이나 NMT Decoder를 통해서 latent variable로써 언어의 확률을 모델링 하고 있지만, 결국 언어를 나타내기 위해서는 해당 확률 모델에서 sampling(또는 argmax)을 하는 과정을 거쳐야 하고 이 과정은 미분이 불가능하거나 미분이 되더라도 gradient가 0이 되어 back-propagation이 불가 합니다.
이러한 이유 때문에 Discriminator의 loss를 Generator에 전달 할 수가 업고, 따라서 GAN을 NLP에는 적용할 수 없는 인식이 지배적이었습니다. 하지만 강화학습을 사용함으로써 Adversarial learning을 NLP에도 우회적으로 사용할 수 있게 되었습니다.
참고로 Reparameterization Trick을 이용해 이 문제를 해결하려는 시도들도 있습니다. Gumbel Softmax [Jang at el.2016]가 대표적입니다. 이를 활용하면 gradient를 전달 할 수 있기 때문에, policy gradient 없이 문제를 해결 할 수도 있습니다.
Why we use RL?
위와 같이 GAN을 사용하기 위함 뿐만이 아니라, 강화학습은 매우 중요합니다. 어떠한 문제를 해결함에 있어서 cross entropy를 쓸 수 있는 분류(classification) 문제나, tensor간의 오류(error)를 구할 수 있는 MSE 등으로 정의 할 수 없는 복잡한 목적함수(objective function)들이 많이 존재하기 때문입니다. (비록 그동안 그러한 objective function으로 문제를 해결하였더라도 문제를 단순화 하여 접근한 것일 수도 있습니다.) 우리는 이러한 문제들을 강화학습을 통해 해결하거나 성능을 더 극대화 할 수 있습니다. 이를 위해서 잘 설계된 reward를 통해서 보다 복잡하고 정교한 task의 문제를 해결 할 수 있습니다.
이제 강화학습에 대해 간단히 다루고, 이를 NLP와 NMT에 어떻게 적용시키는지 다루어 보도록 하겠습니다.