Fully Convolutional Seq2seq
Neural Machine Translation의 최강자는 Google이라고 모두가 여기고 있을 때, Facebook이 과감하게 이 논문[Gehring at el.2017]을 들고 도전장을 내밀었습니다. RNN방식의 seq2seq 대신에 오직 convolutional layer만을 이용한 방식의 seq2seq를 들고 나와, 기존의 방식에 대비해서 성능과 속도 두마리 토끼를 모두 잡았다고 주장하였습니다.
Architecture
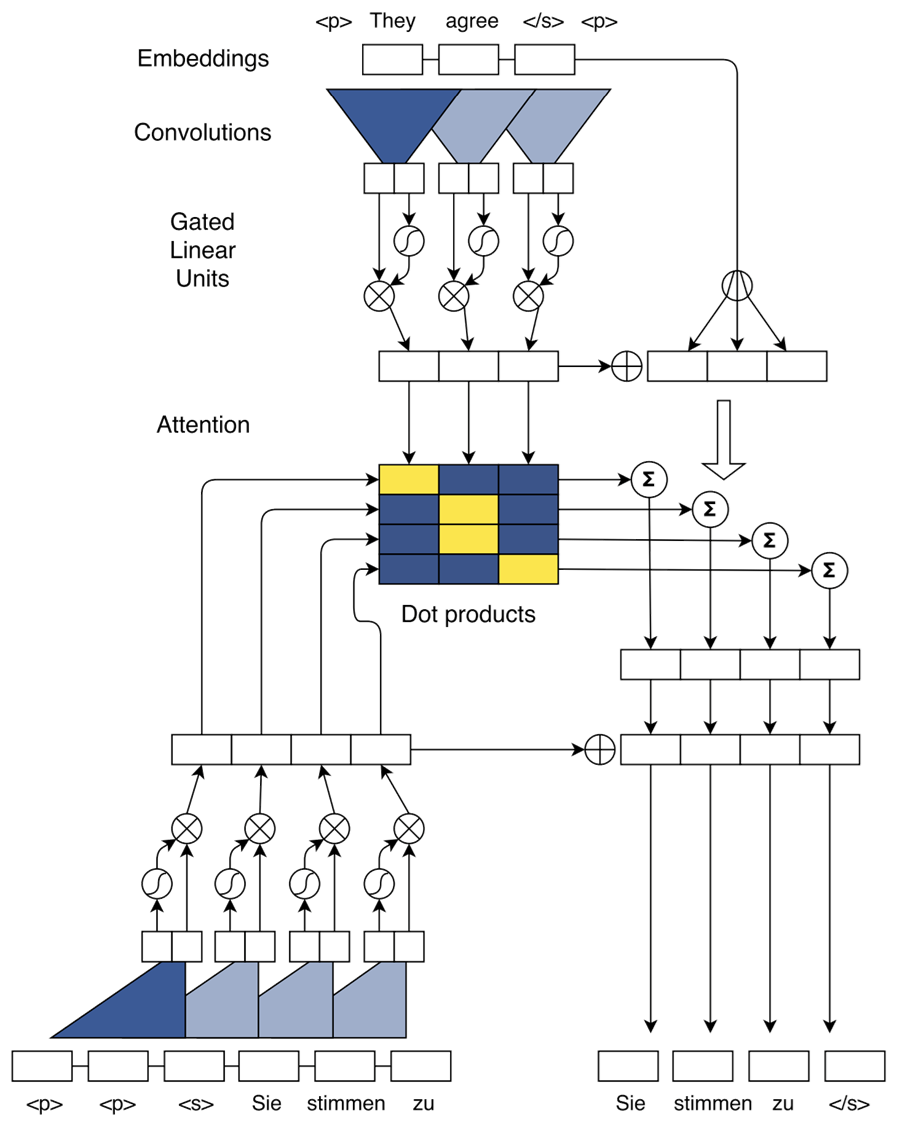
사실 Facebook의 그림 실력은 그닥 칭찬하고 싶지 않습니다. 논문에 있는 그림이 조금 이해하기 어려울 수 있으나 최대한 따라가보도록 하겠습니다.
Position Embedding
이 방식은 RNN을 기반으로 하지 않기 때문에 position embedding을 사용하였습니다. RNN을 사용하면 우리가 직접적으로 위치 정보를 명시하지 않아도 자연스럽게 위치정보가 encoding 되지만, convolutional layer의 경우에는 이것이 없기 때문에 직접 위치 정보를 주어야 하기 때문입니다.
따라서 word embedding vector와 같은 dimension의 position embedding vector를 구하여 매 time-step마다 더해준 뒤, 상위 layer로 feed forward 하게 됩니다.
하지만 position embedding이 없다고 이 방식이 동작하지 않는 것은 아닙니다. Position embedding의 유무에 따라서 실험결과 BLEU가 최대 0.5 정도 차이가 나기도 합니다.
Convolutional Layer
Convolutional Layer를 사용한 encoder를 설명하기 이전에, 먼저 [Ranzato at el.2015]에서는 단순히 이전 layer의 결과값을 averaging하는 encoder를 제안하였습니다.
위와 같이 단순히 평균을 내는 것만으로도 어느정도의 성능을 낼 수 있었습니다. 만약 여기서 convolution filter를 사용하여 averaging 대신에 convolution연산을 한다면 어떻게 될까요?
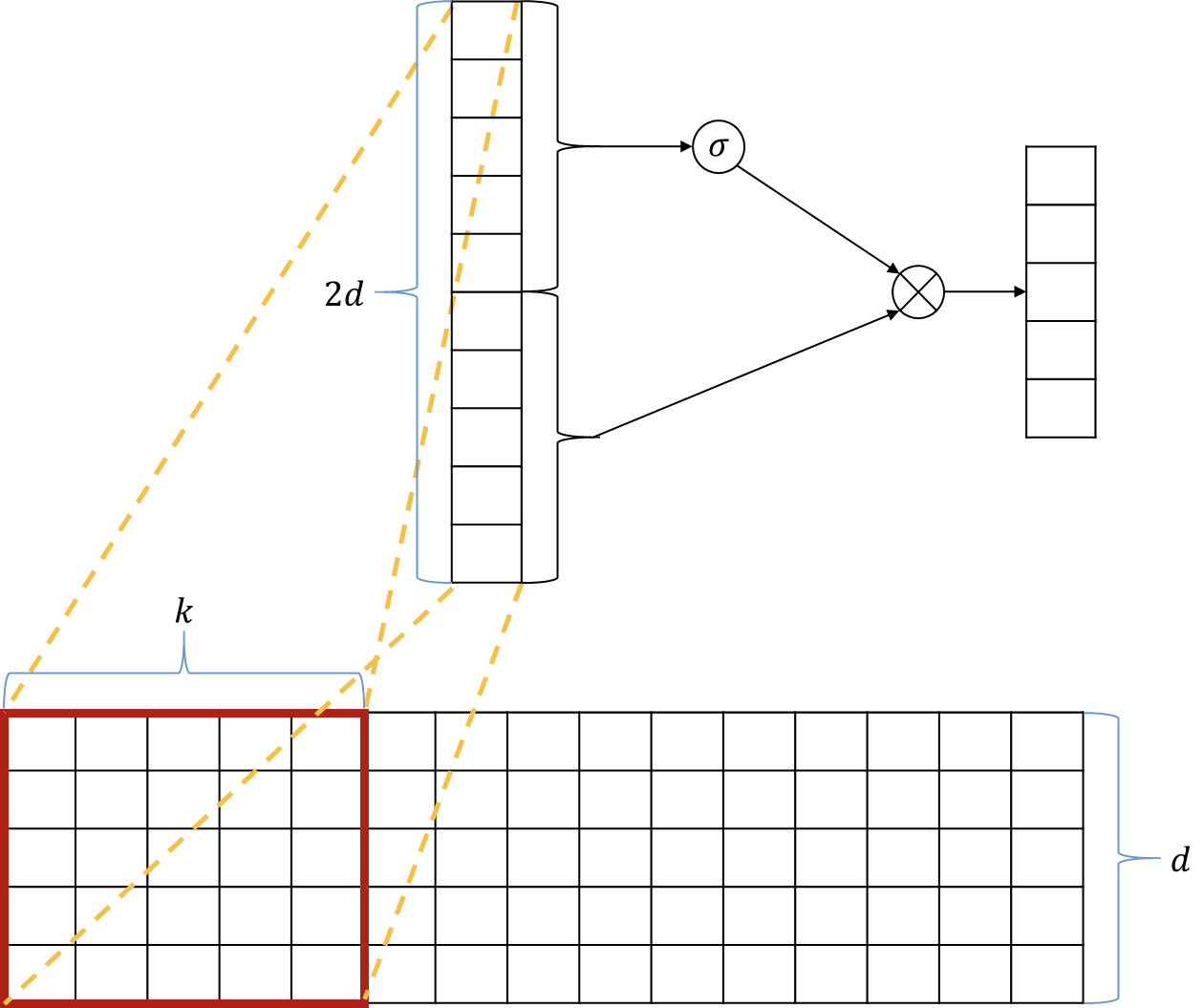
위의 물음에서 출발한 것이 이 논문의 핵심입니다. 따라서 kernel(or window) size 인 convolution filter가 개 channel의 입력을 받아서 convolution 연산을 수행하여 개 channel의 출력을 결과값으로 내놓습니다.
Gated Linear Unit
이 논문에서는 [Dauphine et al.2016]에서 제안한 Gated Linear Unit(GLU)을 사용하였습니다.
GLU를 사용하여 직전 convolution layer에서의 결과값인 vector()를 입력으로 삼아 gate 연산을 수행합니다. 이 연산은 LSTM이나 GRU에서의 gate들과 매우 비슷하게 동작을 수행합니다.
Attention
를 encoder의 출력값, 을 decoder의 번째 layer의 번째 결과값이라고 하고, 를 번째 decoder의 출력값이라고 할 때, attention의 동작은 아래와 같습니다.
이렇게 구해진 context vector 을 (기본적인 attention은 concatenate 하였던 것이 비해서) 아래와 같이 에 그냥 더합니다. 그리고 이것을 다음 decoder layer의 입력으로 사용합니다.
이렇게 번째 layer의 attention이 이루어지게 되는데, 이것을 매 layer마다 넣어주게 됩니다. 이전까지의 seq2seq는 attention layer가 전체 구조에서 한 개만 있었던 것에 비해서 Facebook이 제안한 이 구조에서는 모든 layer마다 나타날 수 있습니다.