Unsupervised NMT
Supervised learning 방식은 높은 정확도를 자랑하지만 labeling 데이터가 필요하기 때문에 데이터 확보, 모델 및 시스템을 구축하는데 높은 비용과 시간이 소요됩니다. 하지만 Unsupervised Learning의 경우에는 데이터 확보에 있어서 훨씬 비용과 시간을 절감할 수 있기 때문에 좋은 대안이 될 수 있습니다.
Parallel corpus vs Monolingual corpus
그러한 의미에서 parallel corpus에 비해서 확보하기 쉬운 monolingual corpus는 좋은 대안이 될 수 있습니다. 소량의 parallel corpus와 다량의 monolingual corpus를 결합하여 더 나은 성능을 확보할 수도 있을 것입니다. 이전 챕터에 다루었던 Back translation과 Copied translation에서 이와 관련하여 NMT의 성능을 고도화 하는 방법을 보여주었습니다. 강화학습에서도 마찬가지로 unsupervised 방식을 적용하려는 시도들이 많이 보이고 있습니다. 다만, 대부분의 방식들은 아직 실제 field에서 적용하기에는 다소 효율성이 떨어집니다.
Unsupervised NMT
위의 Dual Learning 논문과 달리 이 논문[Lample at el.2017]은 오직 Monolingual Corpus만을 사용하여 번역기를 제작하는 방법을 제안하였습니다. 따라서 Unsupervised NMT라고 할 수 있습니다.
이 논문의 핵심 아이디어는 아래와 같습니다. 제일 중요한 것은 encoder가 언어에 상관 없이 같은 내용일 경우에 같은 vector로 encoding할 수 있도록 훈련하는 것 입니다. 이러한 encoder를 만들기 위해서 GAN이 도입되었습니다.
GAN을 NLP에 쓰지 못한다고 해 놓고 GAN을 썼다니 이게 무슨 소리인가 싶겠지만, encoder의 출력값인 vector에 대해서 GAN을 적용한 것이라 discrete한 값이 아닌 continuous한 값이기 때문에 가능한 것 입니다.

이렇게 다른 언어일지라도 동일한 내용에 대해서는 같은 vector로 encoding하도록 훈련 된 encoder의 출력값을 가지고 decoder로 원래의 문장으로 잘 돌아오도록 해 주는 것이 이 논문의 핵심 내용입니다.
특기 할 만한 점은 이 논문에서는 언어에 따라서 encoder와 decoder를 다르게 사용한 것이 아니라 언어에 상관없이 1개씩의 encoder와 decoder를 사용하였습니다. 또한 이 논문[Conneau at el.,2017]에서 제안한 word by word translation 방식으로 pretraining 한 모델을 사용합니다.
이 논문의 훈련은 3가지 관점에서 수행됩니다.
Denoising Autoencoder
이전 챕터에서 다루었듯이 Seq2seq 모델도 결국 Autoencoder의 일종이라고 볼 수 있습니다. 그러한 관점에서 autoencoder(AE)로써 단순 복사(copy) task는 굉장히 쉬운 task에 속합니다. 그러므로 단순히 encoding 한 source sentence를 같은 언어의 문장으로 decoding 하는 것은 매우 쉬운 일이 될 것입니다. 따라서 AE에게 단순히 복사 작업을 지시하는 것이 아닌 noise를 섞어 준 source sentence에서 denoising을 하면서 reconstruction(복원)을 할 수 있도록 훈련해야 합니다. 따라서 이 task의 objective는 아래와 같습니다.
는 source sentence 를 를 통해 noise를 추가하고, 같은 언어 로 encoding과 decoding을 수행한 것을 의미합니다. 는 원문과 복원된 문장과의 차이(error)를 나타냅니다.
Noise Model
Noise Model 는 임의로 문장 내 단어들을 drop하거나, 순서를 섞어주는 일을 합니다. drop rate는 보통 0.1, 순서를 섞어주는 단어사이의 거리는 3정도가 적당한 것으로 설명 합니다.
Cross Domain Training (Translation)
이번엔 이전 iteration의 모델 에서 언어()의 noisy translated된 문장()을 다시 언어() source sentence로 원상복구 하는 task에 대한 objective 입니다.
Adversarial Training
Encoder가 언어와 상관없이 항상 같은 분포로 hyper plane에 projection하는지 검사하기 위한 discriminator가 추가되어 Adversarial Training을 진행합니다.
Discriminator는 latent variable 의 언어를 예측하여 아래의 cross-entropy loss를 minimize하도록 훈련됩니다. 는 같은 언어(language pair)를 의미합니다.
따라서 encoder는 discriminator를 속일 수 있도록(fool) 훈련 되야 합니다.
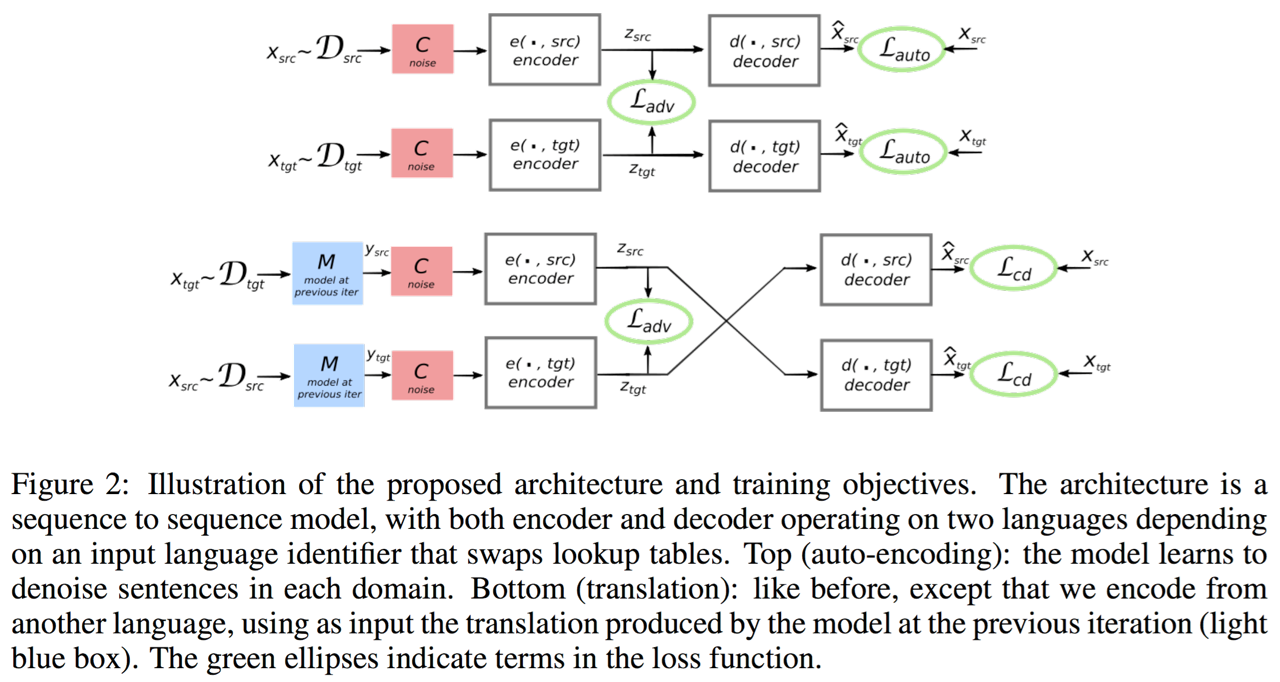
위의 3가지 objective를 결합하면 Final Objective Function을 얻을 수 있습니다.
를 통해서 선형결합(linear combination)을 취하여 기존의 손실함수에 추가 합니다. 이 과정을 pseudo code로 나타내면 아래와 같습니다.

이 논문에서 제안한 방식은 오직 단방향(monolingual) corpus만 존재할 때에 번역기를 만드는 방법에 대해서 다룹니다. 병렬(parallel) corpus가 없는 상황에서도 번역기를 만들 수 있다는 점은 매우 고무적이지만, 이 방법 자체만으로는 실제 필드에서 사용될 가능성은 적어 보입니다. 보통의 경우 필드에서 번역기를 구축하는 경우에는 병렬 corpus가 없는 경우는 드물고, 없다고 하더라도 단방향 corpus만으로 번역기를 구축하여 낮은 성능의 번역기를 확보하기보다는 비용을 들여 병렬 corpus를 직접 구축 한 후에, 병렬 corpus와 다수의 단방향 corpus를 합쳐 번역기를 구축하는 방향으로 나아갈 것이기 때문입니다.