Inference
Overview
이제까지 와 가 모두 주어진 훈련상황을 가정하였습니다만, 이제부터는 만 주어진 상태에서 을 예측하는 방법에 대해서 서술하겠습니다. 이러한 과정을 우리는 Inference 또는 Search 라고 부릅니다. 우리가 기본적으로 이 방식을 search라고 부르는 이유는 search 알고리즘에 기반하기 때문입니다. 결국 우리가 원하는 것은 state로 이루어진 단어(word) 사이에서 최고의 확률을 갖는 path를 찾는 것이기 때문입니다.
Sampling
사실 먼저 우리가 생각할 수 있는 가장 정확한 방법은 각 time-step별 를 고를 때, 마지막 softmax layer에서의 확률 분포(probability distribution)대로 sampling을 하는 것 입니다. 그리고 다음 time-step에서 그 선택()을 기반으로 다음 을 또 다시 sampling하여 최종적으로 가 나올 때 까지 sampling을 반복하는 것 입니다. 이렇게 하면 우리가 원하는 에 가장 가까운 형태의 번역이 완성될 겁니다. 하지만, 이러한 방식은 같은 입력에 대해서 매번 다른 출력 결과물을 만들어낼 수 있습니다. 따라서 우리가 원하는 형태의 결과물이 아닙니다.
Gready Search
우리는 자료구조, 알고리즘 수업에서 수 많은 search 방법에 대해 배웠습니다. DFS, BFS, Dynamic Programming 등. 우리는 이 중에서 Greedy algorithm을 기반으로 search를 구현합니다. 즉, softmax layer에서 가장 값이 큰 index를 뽑아 해당 time-step의 로 사용하게 되는 것 입니다.
Code
def greedy_search(self, src):
mask = None
x_length = None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
else:
x = src
batch_size = x.size(0)
emb_src = self.emb_src(x)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
h_0_tgt, c_0_tgt = h_0_tgt
h_0_tgt = h_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
c_0_tgt = c_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
h_0_tgt = (h_0_tgt, c_0_tgt)
y = x.new(batch_size, 1).zero_() + data_loader.BOS
done = x.new_ones(batch_size, 1).float()
h_t_tilde = None
decoder_hidden = h_0_tgt
y_hats = []
while done.sum() > 0:
emb_t = self.emb_dec(y)
# |emb_t| = (batch_size, 1, word_vec_dim)
decoder_output, decoder_hidden = self.decoder(emb_t, h_t_tilde, decoder_hidden)
context_vector = self.attn(h_src, decoder_output, mask)
h_t_tilde = self.tanh(self.concat(torch.cat([decoder_output, context_vector], dim = -1)))
y_hat = self.generator(h_t_tilde)
# |y_hat| = (batch_size, 1, output_size)
y_hats += [y_hat]
y = torch.topk(y_hat, 1, dim = -1)[1].squeeze(-1)
done = done * torch.ne(y, data_loader.EOS).float()
# |y| = (batch_size, 1)
# |done| = (batch_size, 1)
y_hats = torch.cat(y_hats, dim = 1)
indice = torch.topk(y_hats, 1, dim = -1)[1].squeeze(-1)
# |y_hat| = (batch_size, length, output_size)
# |indice| = (batch_size, length)
return y_hats, indice
Beam Search

하지만 우리는 자료구조, 알고리즘 수업에서 배웠다시피, greedy algorithm은 굉장히 쉽고 간편하지만, 최적의(optimal) 해를 보장하지 않습니다. 따라서 최적의 해에 가까워지기 위해서 우리는 약간의 trick을 첨가합니다. Beam Size 만큼의 후보를 더 tracking 하는 것 입니다.
현재 time-step에서 Top-k개를 뽑아서 (여기서 k는 beam size와 같습니다) 다음 time-step에 대해서 k번 inference를 수행합니다. 그리고 총 개의 softmax 결과 값 중에서 다시 top-k개를 뽑아 다음 time-step으로 넘깁니다. (는 Vocabulary size) 여기서 중요한 점은 두가지 입니다.
- 누적 확률을 사용하여 top-k를 뽑습니다. 이때, 보통 로그 확률을 사용하므로 현재 time-step 까지의 로그확률에 대한 합을 tracking 하고 있어야 합니다.
- top-k를 뽑을 때, 현재 time-step에 대해 k번 계산한 모든 결과물 중에서 뽑습니다.
Beam Search를 사용하면 좀 더 넓은 path에 대해서 search를 수행하므로 당연히 좀 더 나은 성능을 보장합니다. 하지만, beam size만큼 번역을 더 수행해야 하기 때문에 속도에 저하가 있습니다. 다행히도 우리는 이 작업을 mini-batch로 만들어 수행하기 때문에, 병렬처리로 인해서 약간의 속도저하만 생기게 됩니다.
아래는 [Cho et al.2016]에서 주장한 Beam Search의 성능향상에 대한 실험 결과 입니다. Sampling 방법은 단순한 Greedy Search 보다 더 좋은 성능을 제공하지만, Beam search가 가장 좋은 성능을 보여줍니다. 특기할 점은 Machine Translation task에서는 보통 beam size를 10이하로 사용한다는 것 입니다.
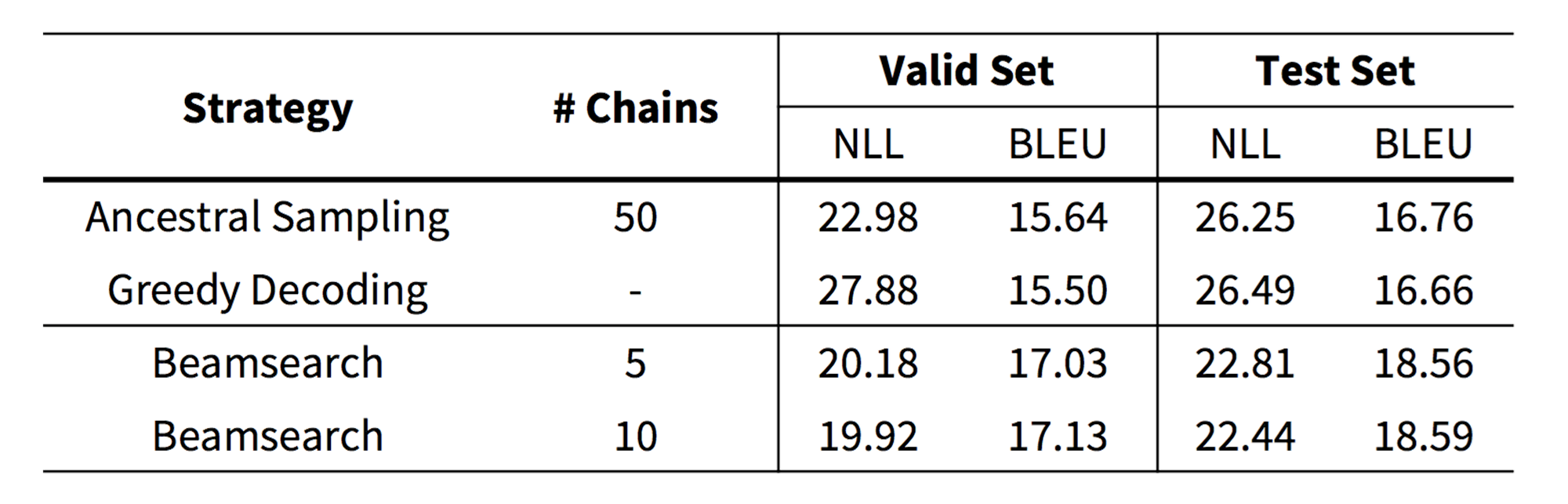 En-Cz: 12m training sentence pairs [Cho, arXiv 2016]
En-Cz: 12m training sentence pairs [Cho, arXiv 2016]
Length Penalty
위의 search 알고리즘을 직접 짜서 수행시켜 보면 한가지 문제점이 발견됩니다. 현재 time-step 까지의 확률을 모두 곱(로그확률의 경우에는 합)하기 때문에 문장이 길어질 수록 확률이 낮아진다는 점 입니다. 따라서 짧은 문장일수록 더 높은 점수를 획득하는 경향이 있습니다. 우리는 이러한 현상을 방지하기 위해서 length penalty를 주어 search가 조기 종료되는 것을 막습니다.
수식은 아래와 같습니다. 불행히도 우리는 2개의 hyper-parameter를 추가해야 합니다. (주의: log확률에 곱하는 것이 맞습니다.)
Code
from operator import itemgetter
import torch
import torch.nn as nn
import data_loader
LENGTH_PENALTY = 1.2
MIN_LENGTH = 5
class SingleBeamSearchSpace():
def __init__(self, hidden, h_t_tilde = None, beam_size = 5, max_length = 255):
self.beam_size = beam_size
self.max_length = max_length
super(SingleBeamSearchSpace, self).__init__()
self.device = hidden[0].device
self.word_indice = [torch.LongTensor(beam_size).zero_().to(self.device) + data_loader.BOS]
self.prev_beam_indice = [torch.LongTensor(beam_size).zero_().to(self.device) - 1]
self.cumulative_probs = [torch.FloatTensor([.0] + [-float('inf')] * (beam_size - 1)).to(self.device)]
self.masks = [torch.ByteTensor(beam_size).zero_().to(self.device)] # 1 if it is done else 0
# |hidden[0]| = (n_layers, 1, hidden_size)
self.prev_hidden = torch.cat([hidden[0]] * beam_size, dim = 1)
self.prev_cell = torch.cat([hidden[1]] * beam_size, dim = 1)
# |prev_hidden| = (n_layers, beam_size, hidden_size)
# |prev_cell| = (n_layers, beam_size, hidden_size)
# |h_t_tilde| = (batch_size = 1, 1, hidden_size)
self.prev_h_t_tilde = torch.cat([h_t_tilde] * beam_size, dim = 0) if h_t_tilde is not None else None
# |prev_h_t_tilde| = (beam_size, 1, hidden_size)
self.current_time_step = 0
self.done_cnt = 0
def get_length_penalty(self, length, alpha = LENGTH_PENALTY, min_length = MIN_LENGTH):
p = (1 + length) ** alpha / (1 + min_length) ** alpha
return p
def is_done(self):
if self.done_cnt >= self.beam_size:
return 1
return 0
def get_batch(self):
y_hat = self.word_indice[-1].unsqueeze(-1)
hidden = (self.prev_hidden, self.prev_cell)
h_t_tilde = self.prev_h_t_tilde
# |y_hat| = (beam_size, 1)
# |hidden| = (n_layers, beam_size, hidden_size)
# |h_t_tilde| = (beam_size, 1, hidden_size) or None
return y_hat, hidden, h_t_tilde
def collect_result(self, y_hat, hidden, h_t_tilde):
# |y_hat| = (beam_size, 1, output_size)
# |hidden| = (n_layers, beam_size, hidden_size)
# |h_t_tilde| = (beam_size, 1, hidden_size)
output_size = y_hat.size(-1)
self.current_time_step += 1
cumulative_prob = y_hat + self.cumulative_probs[-1].masked_fill_(self.masks[-1], -float('inf')).view(-1, 1, 1).expand(self.beam_size, 1, output_size)
top_log_prob, top_indice = torch.topk(cumulative_prob.view(-1), self.beam_size, dim = -1)
# |top_log_prob| = (beam_size)
# |top_indice| = (beam_size)
self.word_indice += [top_indice.fmod(output_size)]
self.prev_beam_indice += [top_indice.div(output_size).long()]
self.cumulative_probs += [top_log_prob]
self.masks += [torch.eq(self.word_indice[-1], data_loader.EOS)]
self.done_cnt += self.masks[-1].float().sum()
self.prev_hidden = torch.index_select(hidden[0], dim = 1, index = self.prev_beam_indice[-1]).contiguous()
self.prev_cell = torch.index_select(hidden[1], dim = 1, index = self.prev_beam_indice[-1]).contiguous()
self.prev_h_t_tilde = torch.index_select(h_t_tilde, dim = 0, index = self.prev_beam_indice[-1]).contiguous()
def get_n_best(self, n = 1):
sentences = []
probs = []
founds = []
for t in range(len(self.word_indice)):
for b in range(self.beam_size):
if self.masks[t][b] == 1:
probs += [self.cumulative_probs[t][b] / self.get_length_penalty(t)]
founds += [(t, b)]
for b in range(self.beam_size):
if self.cumulative_probs[-1][b] != -float('inf'):
if not (len(self.cumulative_probs) - 1, b) in founds:
probs += [self.cumulative_probs[-1][b]]
founds += [(t, b)]
sorted_founds_with_probs = sorted(zip(founds, probs),
key = itemgetter(1),
reverse = True
)[:n]
probs = []
for (end_index, b), prob in sorted_founds_with_probs:
sentence = []
for t in range(end_index, 0, -1):
sentence = [self.word_indice[t][b]] + sentence
b = self.prev_beam_indice[t][b]
sentences += [sentence]
probs += [prob]
return sentences, probs
def batch_beam_search(self, src, beam_size = 5, max_length = 255, n_best = 1):
mask = None
x_length = None
if isinstance(src, tuple):
x, x_length = src
mask = self.generate_mask(x, x_length)
# |mask| = (batch_size, length)
else:
x = src
batch_size = x.size(0)
emb_src = self.emb_src(x)
h_src, h_0_tgt = self.encoder((emb_src, x_length))
# |h_src| = (batch_size, length, hidden_size)
h_0_tgt, c_0_tgt = h_0_tgt
h_0_tgt = h_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
c_0_tgt = c_0_tgt.transpose(0, 1).contiguous().view(batch_size, -1, self.hidden_size).transpose(0, 1).contiguous()
# |h_0_tgt| = (n_layers, batch_size, hidden_size)
h_0_tgt = (h_0_tgt, c_0_tgt)
# initialize beam-search.
spaces = [SingleBeamSearchSpace((h_0_tgt[0][:, i, :].unsqueeze(1),
h_0_tgt[1][:, i, :].unsqueeze(1)),
None,
beam_size,
max_length = max_length
) for i in range(batch_size)]
done_cnt = [space.is_done() for space in spaces]
length = 0
while sum(done_cnt) < batch_size and length <= max_length:
# current_batch_size = sum(done_cnt) * beam_size
# initialize fabricated variables.
fab_input, fab_hidden, fab_cell, fab_h_t_tilde = [], [], [], []
fab_h_src, fab_mask = [], []
# batchify.
for i, space in enumerate(spaces):
if space.is_done() == 0:
y_hat_, (hidden_, cell_), h_t_tilde_ = space.get_batch()
fab_input += [y_hat_]
fab_hidden += [hidden_]
fab_cell += [cell_]
if h_t_tilde_ is not None:
fab_h_t_tilde += [h_t_tilde_]
else:
fab_h_t_tilde = None
fab_h_src += [h_src[i, :, :]] * beam_size
fab_mask += [mask[i, :]] * beam_size
fab_input = torch.cat(fab_input, dim = 0)
fab_hidden = torch.cat(fab_hidden, dim = 1)
fab_cell = torch.cat(fab_cell, dim = 1)
if fab_h_t_tilde is not None:
fab_h_t_tilde = torch.cat(fab_h_t_tilde, dim = 0)
fab_h_src = torch.stack(fab_h_src)
fab_mask = torch.stack(fab_mask)
# |fab_input| = (current_batch_size, 1)
# |fab_hidden| = (n_layers, current_batch_size, hidden_size)
# |fab_cell| = (n_layers, current_batch_size, hidden_size)
# |fab_h_t_tilde| = (current_batch_size, 1, hidden_size)
# |fab_h_src| = (current_batch_size, length, hidden_size)
# |fab_mask| = (current_batch_size, length)
emb_t = self.emb_dec(fab_input)
# |emb_t| = (current_batch_size, 1, word_vec_dim)
fab_decoder_output, (fab_hidden, fab_cell) = self.decoder(emb_t, fab_h_t_tilde, (fab_hidden, fab_cell))
# |fab_decoder_output| = (current_batch_size, 1, hidden_size)
context_vector = self.attn(fab_h_src, fab_decoder_output, fab_mask)
# |context_vector| = (current_batch_size, 1, hidden_size)
fab_h_t_tilde = self.tanh(self.concat(torch.cat([fab_decoder_output, context_vector], dim = -1)))
# |fab_h_t_tilde| = (current_batch_size, 1, hidden_size)
y_hat = self.generator(fab_h_t_tilde)
# |y_hat| = (current_batch_size, 1, output_size)
# separate the result for each sample.
cnt = 0
for space in spaces:
if space.is_done() == 0:
from_index = cnt * beam_size
to_index = (cnt + 1) * beam_size
# pick k-best results for each sample.
space.collect_result(y_hat[from_index:to_index],
(fab_hidden[:, from_index:to_index, :],
fab_cell[:, from_index:to_index, :]),
fab_h_t_tilde[from_index:to_index]
)
cnt += 1
done_cnt = [space.is_done() for space in spaces]
length += 1
# pick n-best hypothesis.
batch_sentences = []
batch_probs = []
for i, space in enumerate(spaces):
sentences, probs = space.get_n_best(n_best)
batch_sentences += [sentences]
batch_probs += [probs]
return batch_sentences, batch_probs