N-gram
Sparseness
이전 섹션에서 언어모델에 대해 소개를 간략히 했습니다. 하지만 만약 그 수식대로라면 우리는 확률들을 거의 구할 수 없을 것 입니다. 왜냐하면 비록 우리가 수천만~수억 문장을 인터넷에서 긁어 모았다고 하더라도, 애초에 출현할 수 있는 단어의 조합의 경우의 수는 무한대에 가깝기 때문입니다. 문장이 조금만 길어지더라도 Count를 구할 수 없어 분자가 0이 되어 확률이 0이 되거나, 심지어 분모가 0이 되어 정의할 수가 없어져버릴 것이기 때문입니다. 이렇게 너무나도 많은 경우의 수 때문에 생기는 문제를 희소성(sparseness or sparsity)문제라고 표현합니다.
Markov Assumption
따라서 sparseness 문제를 해결하기 위해서 Markov Assumption을 도입합니다.
Markov Assumption을 통해, 다음 단어의 출현 확률을 구하기 위해서, 이전에 출현한 모든 단어를 볼 필요 없이, 앞에 개의 단어만 상관하여 다음 단어의 출현 확률을 구하도록 하는 것 입니다. 이렇게 가정을 간소화 하여, 우리가 구하고자 하는 확률을 근사(approximation) 하겠다는 것 입니다. 보통 는 0에서 3의 값을 갖게 됩니다. 즉, 일 경우에는 앞 단어 2개를 참조하여 다음 단어()의 확률을 근사하여 나타내게 됩니다.
이를 이전 chain rule수식에 적용하여, 문장에 대한 확률도 다음과 같이 표현 할 수 있습니다.
이것을 log확률로 표현하면,
우리는 이렇게 전체 문장 대신에 바로 앞 몇 개의 단어만 상관하여 확률 계산을 간소화 하는 방법을 으로 n-gram이라고 부릅니다.
| k | n-gram | 명칭 |
|---|---|---|
| 0 | 1-gram | uni-gram |
| 1 | 2-gram | bi-gram |
| 2 | 3-gram | tri-gram |
위 테이블과 같이 3-gram 까지는 tri-gram이라고 읽지만 4-gram 부터는 그냥 four-gram 이라고 읽습니다. 앞서 설명 하였듯이, 이 커질수록 우리가 가지고 있는 훈련 corpus내에 존재하지 않을 가능성이 많기 때문에, 오히려 확률을 정확하게 계산하는 데 어려움이 있을 수도 있습니다. (예를 들어 훈련 corpus에 존재 하지 않는다고 세상에서 쓰이지 않는 문장 표현은 아니기 때문 입니다.) 따라서 당연히 훈련 corpus의 양이 적을수록 의 크기도 줄어들어야 합니다. 보통은 대부분 어느정도 훈련 corpus가 적당히 있다는 가정 하에서, 3-gram을 가장 많이 사용하고, 훈련 corpus의 양이 많을 때는 4-gram을 사용하기도 합니다. 하지만 이렇게 4-gram을 사용하면 언어모델의 성능은 크게 오르지 않는데 반해, 단어 조합의 경우의 수는 지수적(exponential)으로 증가하기 때문에, 사실 크게 효율성이 없습니다.
이제 위와 같이 3개 단어의 출현 빈도와, 앞 2개 단어의 출현 빈도만 구하면 의 확률을 근사할 수 있습니다. 즉, 아래와 같은 문장 전체의 확률에 대해서
비록 훈련 corpus 내에 해당 문장이 존재 한 적이 없더라도, Markov assumption을 통해서 우리는 해당 문장의 확률을 근사(approximation)할 수 있게 되었습니다.
Generalization
머신러닝의 힘은 보지 못한 case에 대한 대처 능력, 즉 generalization에 있습니다. 따라서, n-gram도 Markov assumption을 통해서 sparseness or sparsity를 해결하는 generalization 능력을 갖게 되었다고 할 수 있습니다. 이제 우리는 이것을 좀 더 향상시킬 수 있는 방법을 살펴 보도록 하겠습니다.
Smoothing (Discounting)
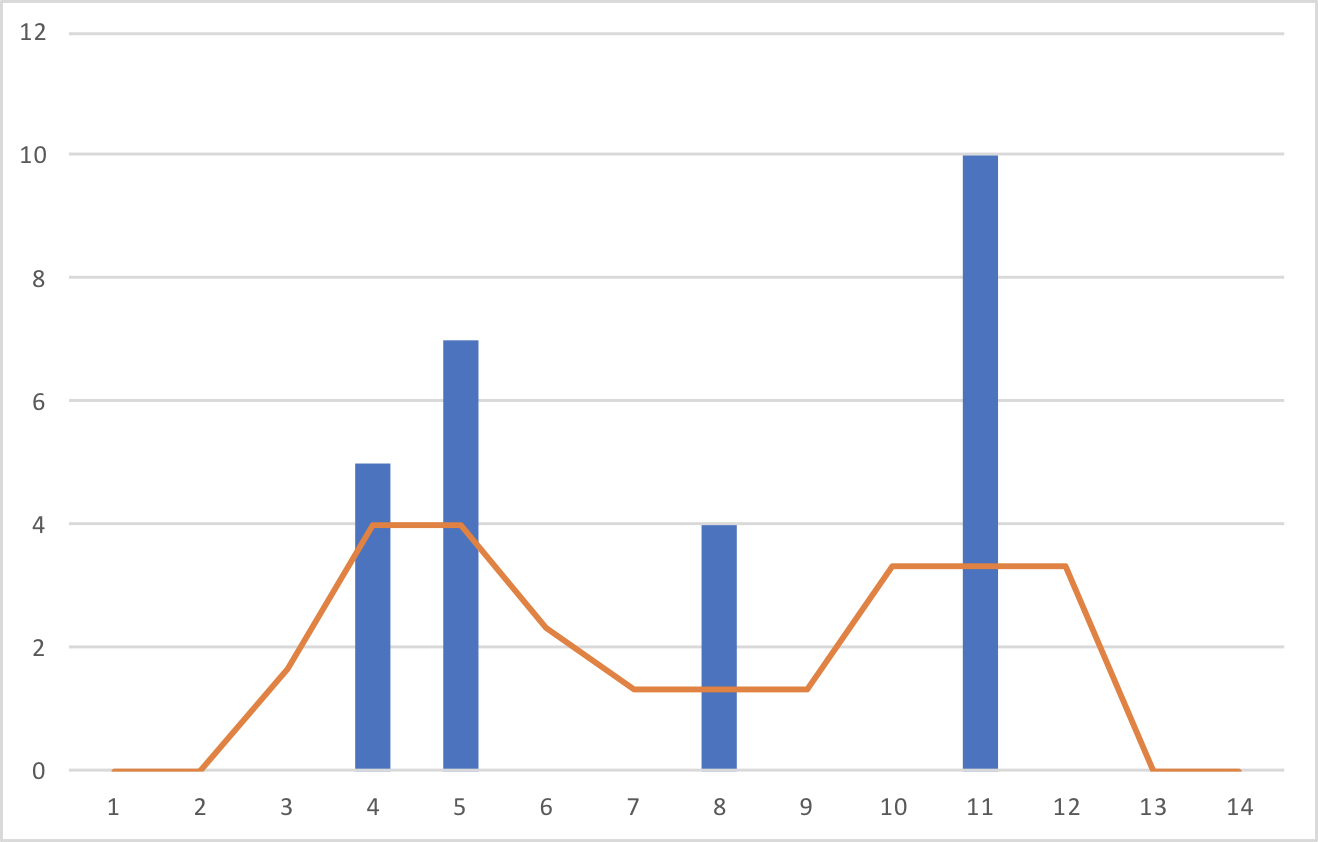
Counting을 단순히 확률 값으로 이용 할 경우 문제점이 무엇이 있을까요? 바로 training corpus에 출현하지 않는 단어 조합에 대한 대처 방법 입니다. 비록, markov assumption을 적용하여 우리는 sparseness를 훨씬 줄였고, 문장의 모든 단어 조합에 대해서 count 할 필요가 없지만, 어찌되었든 그래도 훈련 corpus에 등장하지 않는 경우는 결국 존재 할 것인데, 그 경우인 unseen word sequence라고 해서 등장 확률이 0이 되면 맞지 않습니다. 따라서 counting 값 또는 확률 값을 좀 더 다듬어 줘야 할 필요성이 있습니다. 아래 파란색 bar와 같이 들쭉날쭉한 counting 값을 주황색 line으로 smooth하게 바꾸어 주기 때문에 smoothing 또는 discounting이라고 불립니다. 그럼 그 방법에 대해 살펴보겠습니다.
Absolute Smoothing
[Church et al.1991]은 bigram에 대해서 실험을 한 결과를 제시하였습니다. Training corpus에서 n번 나타난 bigram에 대해서, test corpus에서 나타난 횟수를 count하고 평균을 낸 것 입니다. 그 결과는 아래와 같습니다.

재미있게도, 0번과 1번 나타난 bigram을 제외하면, 2번부터 9번 나타난 bigram의 경우에는 test corpus에서의 출현 횟수는 training corpus 출현 횟수보다 약 0.75번 정도 적게 나타났다는 것 입니다. 즉, counting에서 상수 d를 빼주는 것과 같다는 것입니다.
Kneser-Ney Smoothing
[Kneser et al.1995]은 여기에서 한발 더 나아가, KN discount를 제시하였습니다.
KN discounting의 main idea는 단어 w가 누군가(v)의 뒤에서 출현 할 때, 얼마나 다양한 단어 뒤에서 출현하는지를 알아내는 것 입니다. 그래서 다양한 단어 뒤에 나타나는 단어일수록, unseen word sequence로써 나타날 확률이 높다는 것 입니다.
예를 들어, 우리 책은 machine learning과 deep learning을 다루는 책 이므로, 책 내에서 learning이라는 keyword의 빈도는 굉장히 높을 것 입니다. 하지만, 해당 단어는 주로 machine과 deep뒤에서만 나타났다고 해 보죠. learning이라는 단어에 비해서, laptop이라는 표현의 빈도는 낮을 것 입니다. 하지만 learning과 같이 특정 단어의 뒤에서 대부분 나타나기 보단, 자유롭게 나타났을 것 같습니다. KN discounting은 이 경우, laptop이 unseen word sequence에서 나타날 확률이 더 높다고 가정 하는 것 입니다. 한마디로 낯을 덜 가리는 단어를 찾아내는 것 입니다.
KN discounting은 을 아래와 같이 모델링 합니다. 즉, w와 같이 나타난 v들의 집합의 크기가 클 수록 은 클 것이라고 가정 합니다.
위의 수식은 이렇게 나타내 볼 수 있습니다. w와 같이 나타난 v들의 집합의 크기를, v, w'가 함께 나타난 집합의 크기의 합으로 나누어 줍니다.
이렇게 우리는 를 정의 할 수 있습니다.
Back-off
너무 긴 word sequence는 실제 training corpus에서 굉장히 희귀(rare, sparse)하기 때문에, 우리는 Markov assumption을 통해서 generalization을 얻을 수 있었습니다. 그럼 그것을 응용해서 좀 더 나아가 보도록 하겠습니다.
아래 수식을 보면 특정 n-gram의 확률을 n보다 더 작은 sequence에 대해서 확률을 구하여 linear combination을 계산 하는 것을 볼 수 있습니다. 아래와 같이 n보다 더 작은 sequence에 대해서도 확률을 가져옴으로써 smoothing을 통해 generalization 효과를 좀 더 얻을 수 있습니다.
또한, 다음 단어를 예측 해 내는 task를 하는 실전(inference)에서도, training corpus에 존재하지 않는 unseen n-gram에 대해서도 training corpus에 나타났던 word sequence가 있을 때까지 back-off하여, 다음 단어의 확률을 예측 해 볼 수 있습니다.
Interpolation
Interpolation에 의한 generalization을 살펴 보도록 하겠습니다. Interpolation은 두 다른 Language Model을 linear하게 일정 비율()로 섞어 주는 것 입니다. Interpolation을 통해 얻을 수 있는 효과는, general한 corpus를 통해 구축한 language model을, 필요에 따라 다른 특정 domain의 (양이 적은) corpus를 통해 구축한 domain specific(or adapted) language model과 섞어 주는 것 입니다. 이를 통해 일반적인 언어 모델을 해당 domain에 특화 된 언어 모델로 만들 수 있습니다.
예를 들어 의료 쪽 음성인식(ASR) 또는 기계번역(MT) 시스템을 구축한다고 가정 해 보겠습니다. 그렇다면 기존의 general한 corpus를 통해 생성한 language model의 경우에는 의료 용어라던가 표현이 낯설 수도 있습니다.

따라서 일반적인 대화에서와 다른 의미를 지닌 단어가 나올 수도 있고, 일반적인 대화에서는 희귀(rare)한 표현(word sequence)가 훨씬 더 자주 등장 할 수 있습니다. 이런 case들에 잘 대처하기 위해서 해당 domain corpus로 생성한 language model을 섞어주어 해당 domain에 특화 시킬 수 있습니다.
Conclusion
n-gram 방식은 count를 통해 확률을 근사하기 때문에 굉장히 쉽고 간편합니다. 대신에 단점도 명확합니다. 훈련 corpus에 등장하지 않은 단어 조합은 확률을 정확하게 알 수 없습니다. 따라서 Markov assumption을 통해서 단어 조합에 필요한 조건을 간소화 시키고, 더 나아가 Smoothing과 Back-off 방식을 통해서 남은 단점을 보완하려 했습니다만, 이 또한 근본적인 해결책은 아니므로 실제로 음성인식이나 통계기반 기계번역에서 쓰이는 언어모델 어플리케이션 적용에 있어서 큰 난관으로 작용하였습니다. 하지만, 워낙 간단하고 명확하기 때문에 성공적으로 음성인식, 기계번역 등에 정착하였고 십수년동안 널리 사용되어 왔습니다.