Improve Neural Machine Translation using Monolingual Corpora
번역 시스템을 훈련하기 위해서는 다량의 Parallel Corpus(병렬 말뭉치)가 필요합니다. 필자의 경험상 대략 300만 문장쌍이 있으면 완벽하지는 않지만 나름 쓸만한 번역기가 나오기 시작합니다. 하지만 인터넷에는 정말 수치로 정의하기도 힘들 정도의 monolingual corpus가 널려 있는데 반해서, 이러한 parallel corpus을 대량으로 얻는 것은 굉장히 어려운 일입니다. 또한, monolingual corpus가 그 양이 많기 때문에 실제 우리가 사용하는 언어의 확률분포에 좀 더 가까울 수 있고, 따라서 언어모델을 구성함에 있어서 훨씬 유리합니다. 즉, 앞으로 소개할 기법들은 다량의 monolingual corpus를 활용하여 해당 언어의 language model을 보완하는 것이 주 목적입니다. 이번 섹션은 이러한 값싼 monolingual corpus를 활용하여 Neural Machine Translation system의 성능을 쥐어짜는 방법들에 대해서 다룹니다.
Language Model Ensemble
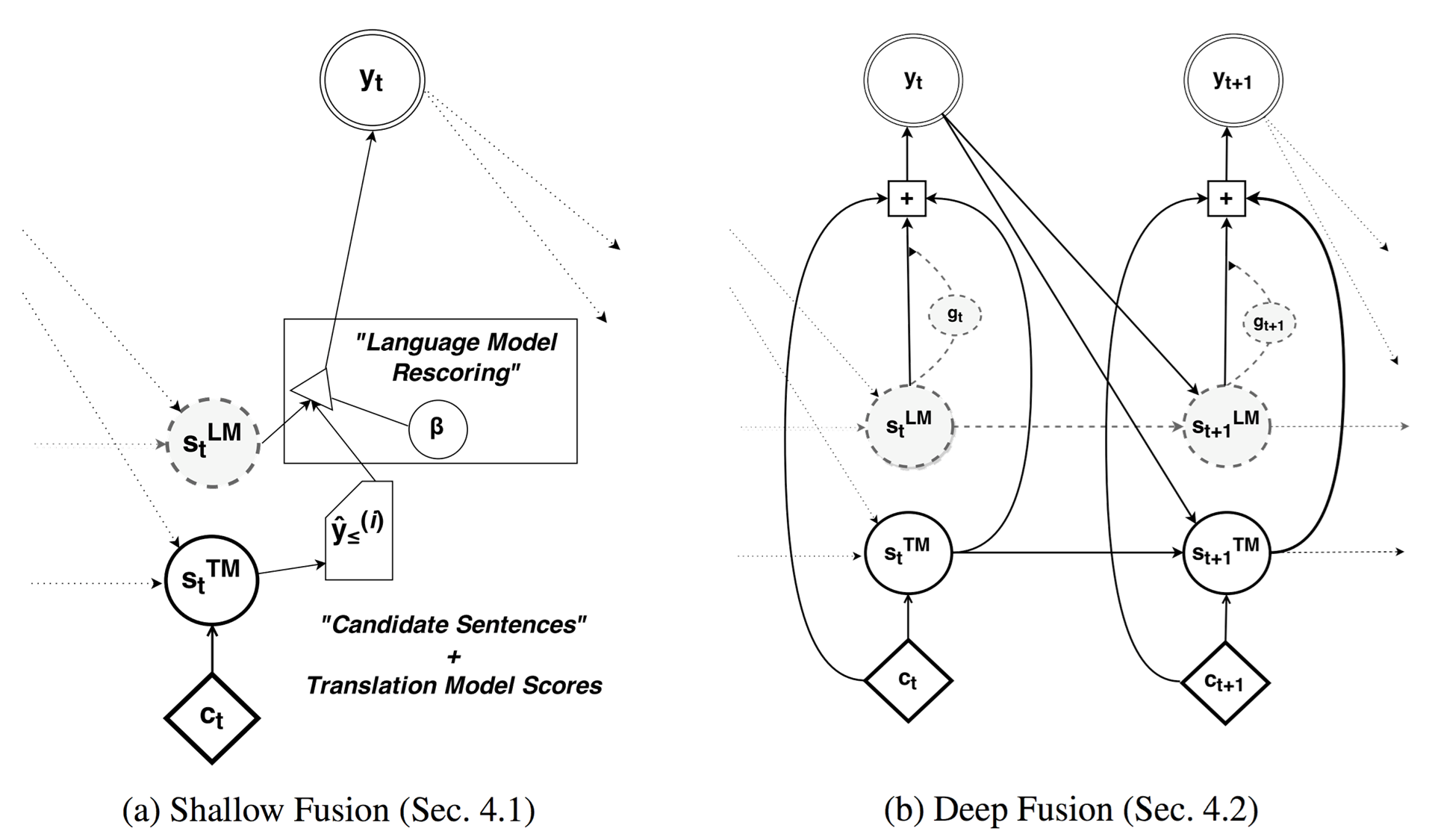
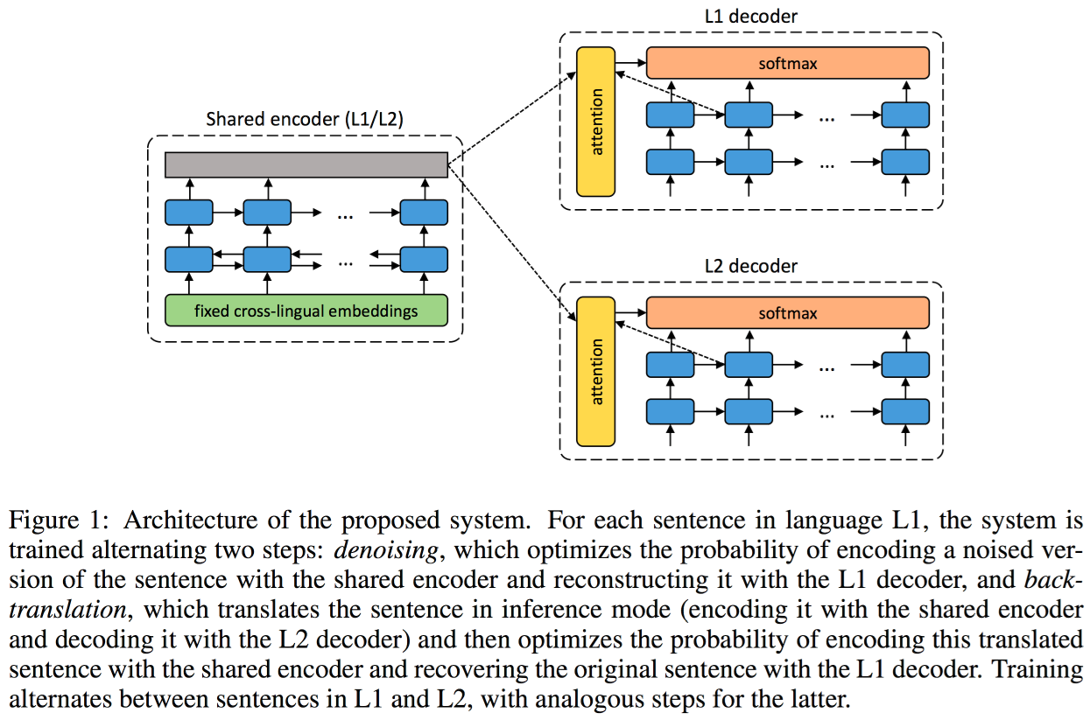
이 방법은 Bengio 교수의 연구실에서 쓴 paper인 [Gulcehre at el.2015]에서 제안 된 방법입니다. Language Model을 explicit하게 ensemble하여 디코더의 성능을 올리고자 시도하였습니다. 두개의 다른 모델을 쓴 shallow fusion 방법 보다, LM을 Seq2seq에 포함시켜 end2end training을 하여 한개의 모델로 만든 deep fusion 방법이 좀 더 나은 성능을 나타냈습니다. 두 방식 모두 Monolingual corpus를 활용하여 Language Model을 pre-train한 이후 실제 번역기를 훈련시킬 때에는 weight를 freeze 한 상태로 seq2seq 모델을 훈련합니다.
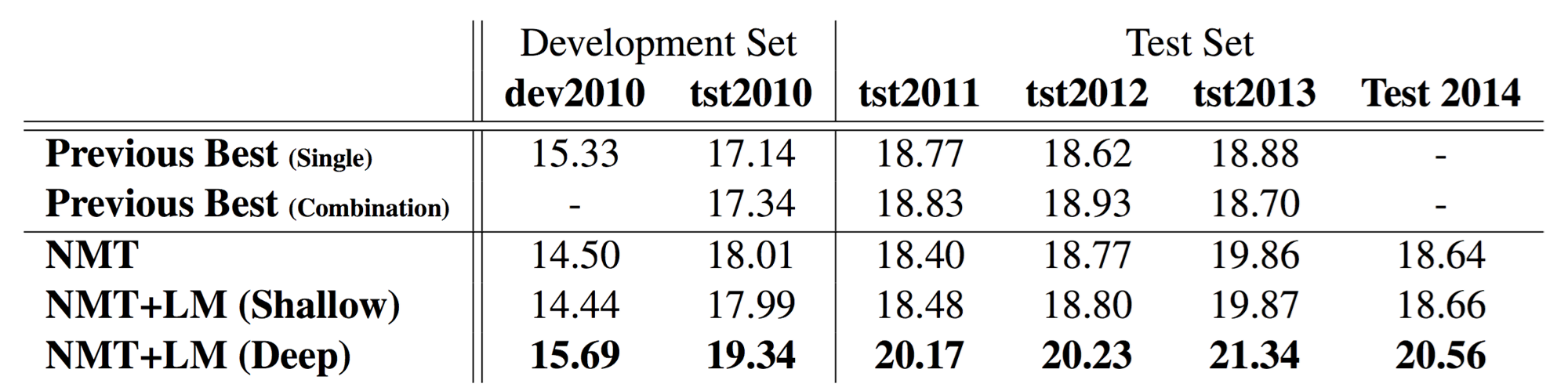
성능상으로는 뒤에 다룰 내용들보다 성능 상의 gain이 적지만, 그 내용이 방법의 장점은 Monolingual corpus를 전부 활용 할 수 있다는 것입니다.
Dummy source sentence translation
아래의 내용들은 전부 Edinburgh 대학의 Nematus 번역시스템
에서 제안되고 사용된 내용들입니다. 이 논문([Sennrich et al.2015])의 저자인 Rico Sennrich는 explicit하게 LM을 ensemble 하는 대신, decoder로 하여금 monolingual corpus를 학습할 수 있게 하는 방법을 제안하였습니다. 예전 챕터에서 다루었듯이, 디코더는 Conditional Neural Network Language Model이라고 할 수 있는데, source sentence인 를 빈 입력을 넣어줌으로써, (그리고 Attention등을 모두 dropout 시켜 끊어줌으로써) condition을 없애는 것이 이 방법의 핵심입니다. 저자는 이 방법을 사용하면 decoder가 monolingual corpus의 language model을 학습하는 것과 같다고 하였습니다.
Back translation
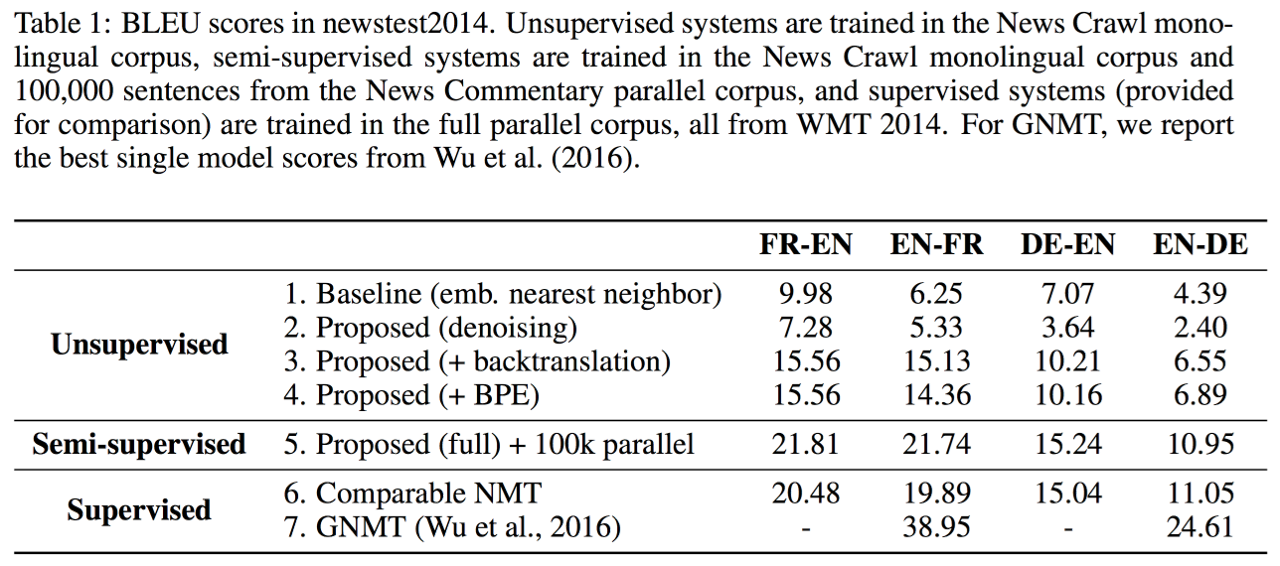
그리고 같은 논문에서 좀 더 발전된 다른 방법을 제시하였습니다. 이 방법은 기존의 훈련된 반대 방향 번역기를 사용하여 monolingual corpus를 기계번역하여 synthetic parallel corpus를 만들어 이것을 훈련에 사용하는 방식 입니다. 중요한 점은 기계번역에 의해 만들어진 synthetic parallel corpus를 사용할 때, 반대방향의 번역기의 훈련에 사용한다는 것 입니다.
![]()
예를 들어, 한국어 monolingual corpus가 있을 때, 이것을 기존에 훈련된 한영번역기에 기계번역시켜 한-영 synthetic parallel corpus를 만들고, 이것을 영한번역기를 훈련시키는데 사용하는 것 입니다. 이러한 방법의 특성 때문에 back translation 이라고 명명되었습니다.

위의 Table은 Dummy source translation(==monolingual)과 back translation(==synthetic) 방식에 대해서 성능을 실험한 결과 입니다. 두가지 방법 모두 사용하였을 때에 성능이 제법 향상된 것을 볼 수 있습니다. Parallel corpus와 거의 같은양의 corpus가 각각 사용되었습니다. 위에서 언급했듯이, explicit한 Language Model Ensemble 방식에서는 corpus양의 제한이 없었지만, 이 방식에서는 기존의 parallel corpus와 차이 없이 섞어서 동시에 훈련에 사용하기 때문에, monolingual corpus의 양이 parallel corpus 보다 많아질 경우 주객전도 현상이 일어날 수 있습니다. 따라서 그 양을 제한하여 훈련에 사용하였습니다.
Copied translation
이 방식은 같은 저자인 Rich Sennrich에 의해서 [Currey et al.2017] Copied Monolingual Data Improves Low-Resource Neural Machine
Translation 에서 제안 되었습니다. 기존의 Dummy source sentence translation 방식에서 좀 더 나아진 방식입니다. 기존의 방식 대신에 source side와 target side에 identical한 같은 데이터를 넣어 훈련시키는 것 입니다. 기존의 dummy source sentence 방식은 encoder에서 decoder로 가는 길을 훈련시에 dropout 처리 해주어야 했지만, 이 방식은 그럴 필요가 없어진 것이 장점입니다. 하지만 source language의 vocabulary에 target language의 vocabulary가 포함되어야 하는 불필요함을 감수해야 합니다.

Conclusion
위와 같이 여러 방법들이 제안되었지만, 위의 방법 중에서는 구현 방법의 용이성과 효율성 때문에 back translation이 가장 많이 쓰이는 추세 입니다. Back translation 기법은 간단한 방법임에도 불구하고 효과적으로 성능 향상을 얻을 수 있습니다.
Unsupervised Neural Machine Translation