Recent Trends in NLP
Conquering on Basic NLP
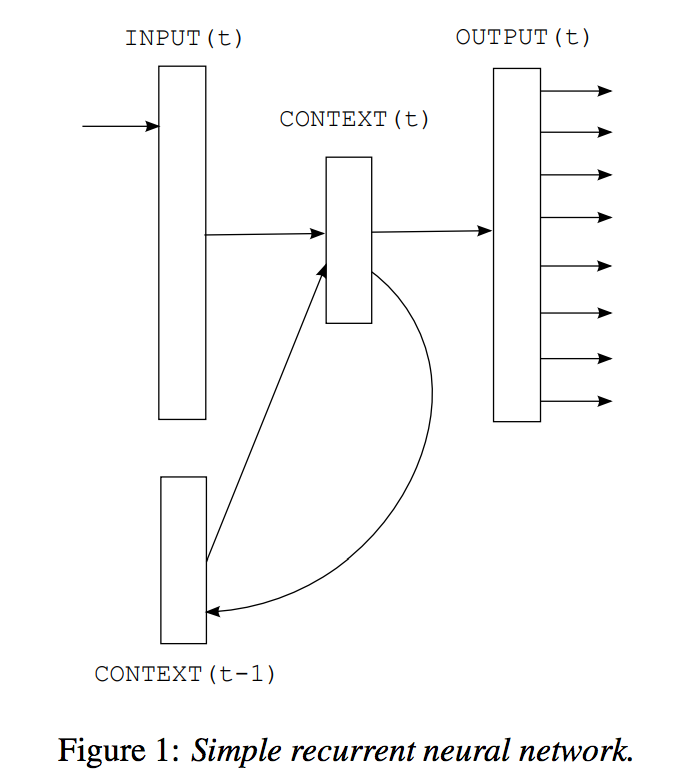
이전에 다루었던 대로, 인공지능의 다른 분야에 비해서 NLP는 가장 늦게 빛을 보기 시작하였다고 하였지만, 여러 task에 deep learning을 적용하려는 시도는 많이 이루어졌고, 진전은 있었습니다. 2010년에는 RNN을 활용하여 language modeling을 시도[Mikolov et al.2010][Sundermeyer at el.2012]하여 기존의 n-gram 기반의 language model의 한계를 극복하려 하였습니다. 그리하여 기존의 n-gram 방식과의 interpolation을 통해서 더 나은 성능의 language model을 만들어낼 수 있었지만, 기존에 langauge model이 사용되던 음성인식과 기계번역에 적용되기에는 구조적인 한계(Weighted Finite State Transeducer, WFST의 사용)로 인해서 더 큰 성과를 거둘 수는 없었습니다. -- 애초에 n-gram 기반 언어모델의 한계는 WFST에 기반하였기 때문이라고도 볼 수 있습니다. 닭이 먼저냐, 달걀이 먼저냐의 문제와 같음.
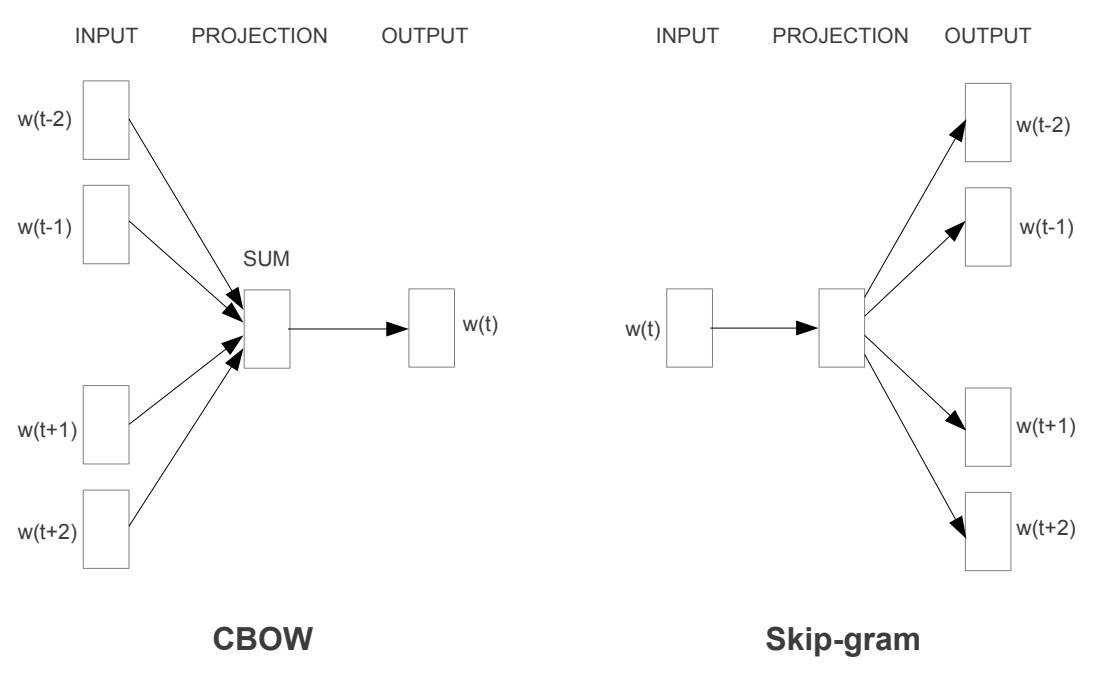
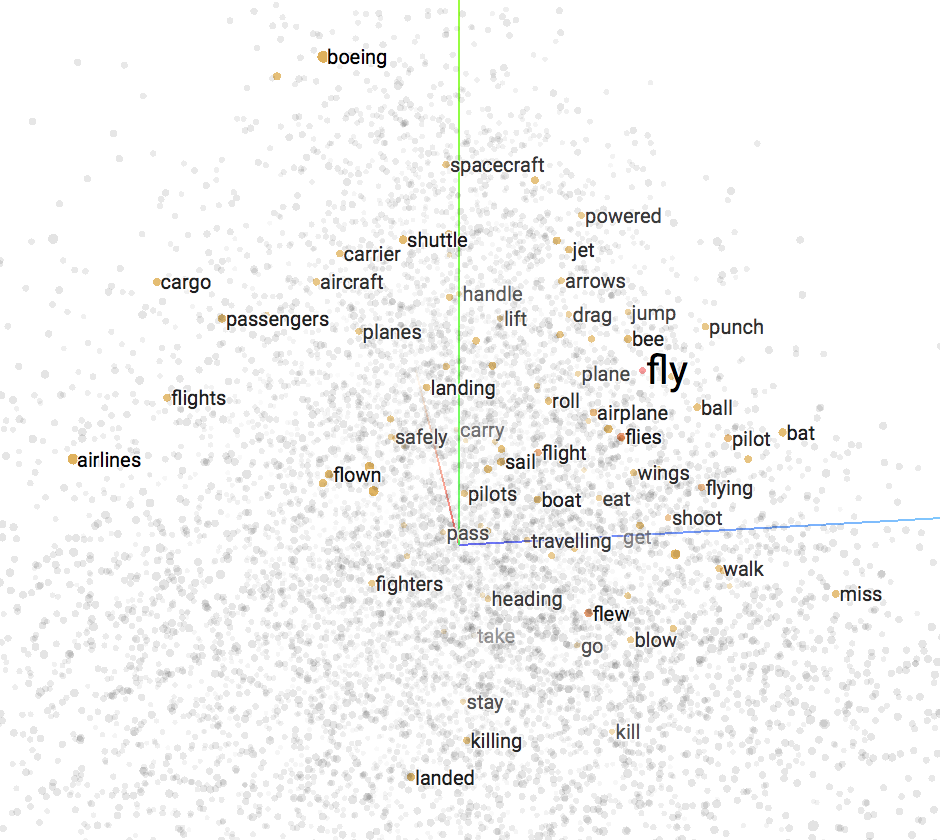
그러던 와중에 Mikolov는 2013년 Word2Vec[Mikolov et al.2013]을 발표합니다. 단순한 구조의 neural network를 사용하여 효과적으로 단어들을 hyper plane(또는 vector space)에 성공적으로 projection(투영) 시킴으로써, 본격적인 NLP 문제에 대한 딥러닝 활용의 신호탄을 쏘아 올렸습니다. 아래와 같이 우리는 고차원의 공간에 단어가 어떻게 배치되는지 알 수 있음으로 해서, deep learning을 활용하여 NLP에 대한 문제를 해결하고자 할 때에 network 내부는 어떤식으로 동작하는지에 대한 insight를 얻을 수 있었습니다.
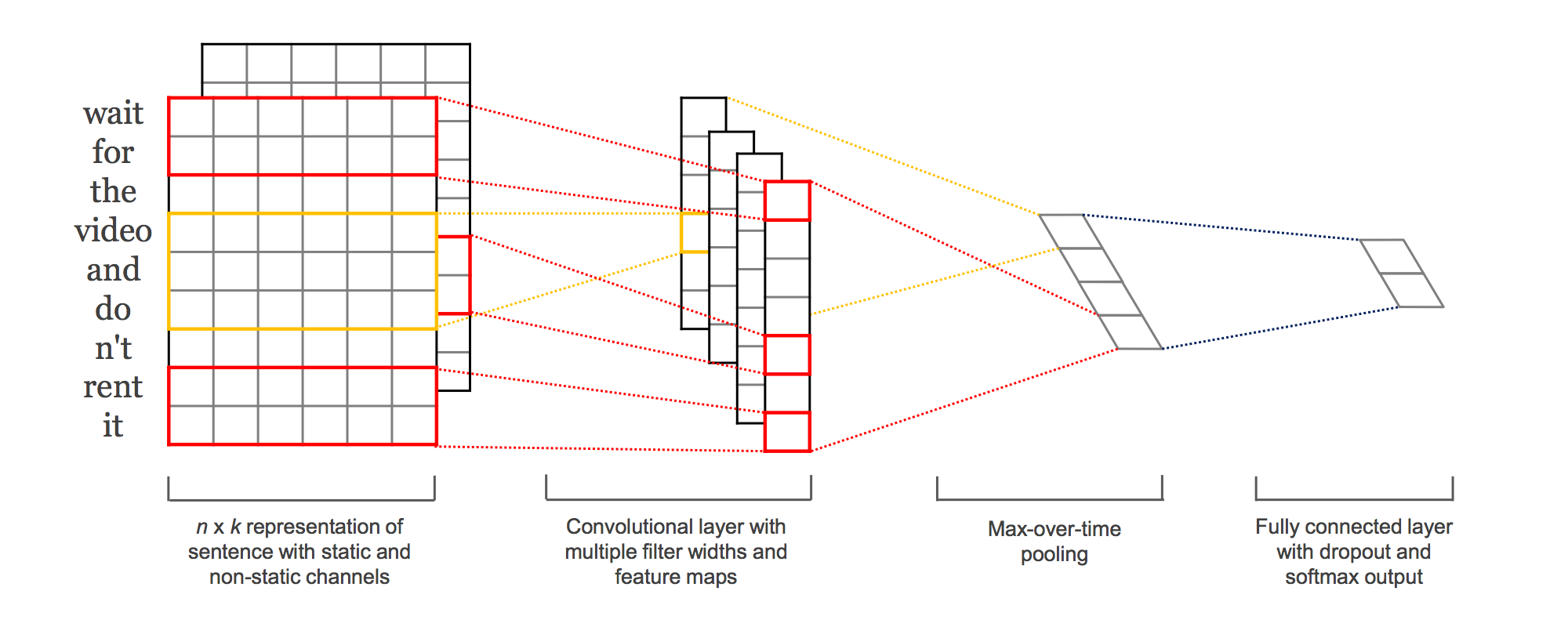
이때까지는 문장이란 단어들의 time series이기 때문에, 당연히 Recurrent Neural Network(RNN)을 통해 해결해야 한다는 고정관념이 팽배해 있었습니다 -- Image=CNN, NLP=RNN. 하지만 2014년, Kim은 CNN만을 활용해 기존의 Text Classification보다 성능을 끌어올린 방법을 제시[Kim et al.2014]하며 한차례 파란을 일으킵니다. 이 방법은 word embedding vector와 결합하여 더 성능을 극대화 할 수 있었습니다. 위의 paper를 통해서 학계는 NLP에 대한 시각을 한차례 더 넓힐 수 있게 됩니다.
이외에도 POS(Part-of-Speech) tagging, Sentence parsing, NER(Named Entity Recognition), SR(Semantic Role) labeling등에서도 기존의 state of the art를 뛰어넘는 성과를 이루냅니다. 하지만 딥러닝의 등장으로 인해 대부분의 task들이 end-to-end를 통해 문제를 해결하고자 함에따라, (또한, 딥러닝 이전에도 이미 매우 좋은 성과를 내고 있었거나, 딥러닝의 적용 후에도 큰 성능의 차이가 없음에) 큰 파란을 일으키지는 못합니다. -- 당연히 그정도는 좋아지는거 아니야? 이런 느낌...?
Flourish of NLG

2014년 NLP에 큰 혁명이 다가옵니다. Sequence-to-Sequence의 발표[Sutskever et al.2014]에 이어, Attention 기법이 개발되어 성공적으로 기계번역에 적용[Bahdanau et al.2014]하여 큰 성과를 거둡니다. 이에 NLP분야는 일대 혁명을 맞이합니다. 기존의 한정적인 적용 사례에서 벗어나, 주어진 정보에 기반하여 자유롭게 문장을 생성할 수 있게 된 것입니다. 따라서, 기계번역 뿐만 아니라, summarization, 챗봇 등 더 넓고 깊은 주제의 NLP의 문제를 적극적으로 해결해보려 시도 할 수 있게 되었습니다.
또한, 이와 같이 NLP 분야에서 딥러닝을 활용하여 큰 성과를 거두자, 더욱더 많은 연구가 활기를 띄게 되어 관련한 연구가 쏟아져 나오게 되었고, 기계번역은 가장 먼저 end-to-end 방식을 활용하여 상용화에 성공하였을 뿐만 아니라, Natural Language Processing에 대한 이해도가 더욱 높아지게 되었습니다.
Advanced Technique with Memory
Attention이 큰 성공을 거두자, continuous한 방식으로 memory에 access하는 기법에 대한 관심이 커졌습니다. 곧이어 Neural Turing Machine(NTM)[Graves et al.2014]이 대담한 이름대로 큰 파란을 일으키며 주목을 받았습니다. Continuous한 방식으로 memory에서 정보를 read/write하는 방법을 제시하였고, 이어서 Differential Neural Computer (DNC)[Graves et al.2016]가 제시되며 memory 활용방법에 대한 관심이 높아졌습니다.
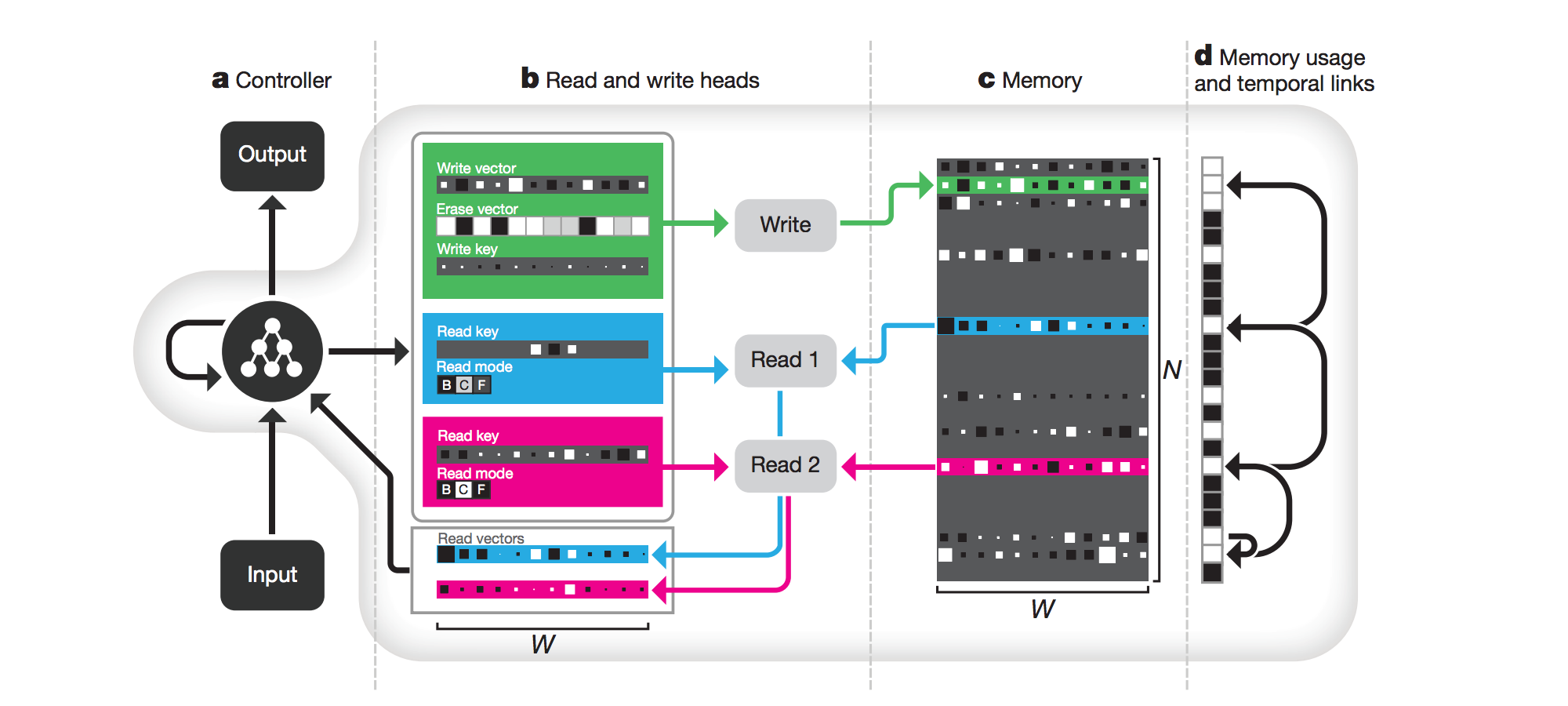
이러한 memory를 활용하는 기법은 Memory Augmented Neural Network(MANN)이라 불리우며, 이 기법이 발전한다면 최종적으로는 우리가 원하는 정보를 neural network 상에 저장하고 필요할 때 잘 조합하여 꺼내쓰는, Question Answering (QA) task와 같은 문제에 효율적으로 대응 할 수 있게 될 것입니다.
참고사이트:
Convergence of NLP and Reinforcement Learning
일찌감치 Variational Auto Encoder(VAE)[Kingma et al.2013]와 Generative Adversarial Networks(GAN)[Goodfellow et al.2014]을 통해 Computer Vision 분야는 기존의 discriminative learning 방식을 벗어나 generative learning에 관심이 옮겨간 것과 달리, NLP분야는 그럴 필요가 없었습니다. 이미 language modeling 자체가 문장에 대한 generative learning이기 때문 입니다.
하지만, 기계번역의 연구결과서 큰 성과를 띄면서 학계는 다른 어려움에 부딪히게 됩니다. Deep learning에서 사용하는 cross entropy와 실제 기계번역을 위한 objective function과 괴리(discrepancy)가 있었기 때문입니다. 따라서, 마치 Computer Vision에서 기존의 MSE loss의 한계를 벗어나기 위해 GAN을 도입한 것 처럼, 기존의 loss function과 다른 무엇인가가 필요하였습니다.
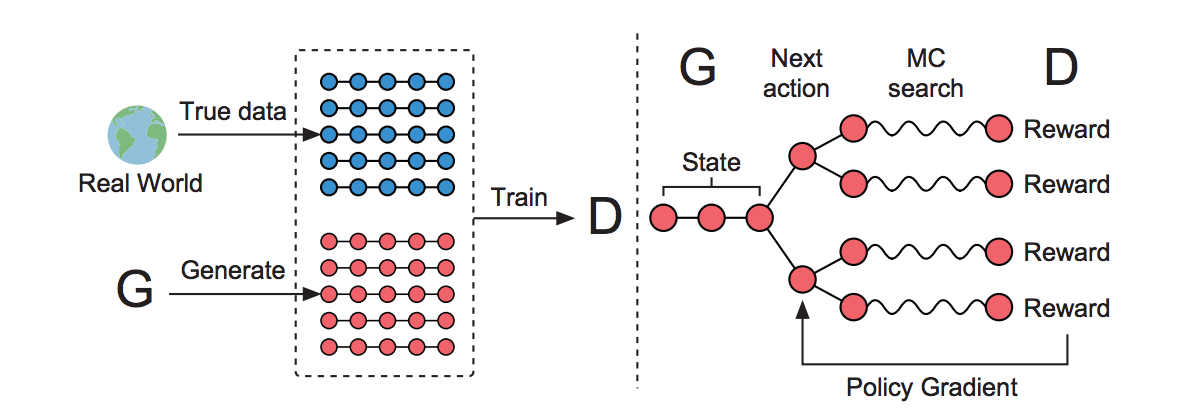
이때 성공적으로 강화학습의 policy gradients 방식을 NLP에 적용함으로써[Bahdanau et al.2016][Yu et al.2016], 마치 vision분야의 adversarial learning을 NLP에서도 흉내낼 수 있게 되었습니다. 이렇게, 강화학습(RL)을 사용하여 실제 task에서의 objective function으로부터 reward를 받을 수 있게 됨에 따라, 더욱 성능을 극대화 할 수 있게 되었습니다.