Neural Network Language Model
Against to Sparseness
앞서 설명한 것과 같이 기존의 n-gram 기반의 언어모델은 간편하지만 훈련 데이터에서 보지 못한 단어의 조합에 대해서 상당히 취약한 부분이 있었습니다. 그것의 근본적인 원인은 n-gram 기반의 언어모델은 단어간의 유사도를 알 지 못하기 때문입니다. 예를 들어 우리에게 훈련 corpus로 아래와 같은 문장이 주어졌다고 했을 때,
- 고양이는 좋은 반려동물 입니다.
사람은 단어간의 유사도를 알기 때문에 다음 중 어떤 확률이 더 큰지 알 수 있습니다. 하지만, 컴퓨터는 훈련 corpus에 해당 n-gram이 존재하지 않으면, count를 할 수 없기 때문에 확률을 구할 수 없고, 따라서 확률 간 비교를 할 수도 없습니다.
비록 강아지가 개의 새끼이고 포유류에 속하는 가축에 해당한다는 깊고 해박한 지식이 없을지라도, 강아지와 고양이 사이의 유사도가 자동차와 고양이 사이의 유사도보다 높은 것을 알기 때문에 자동차 보다는 강아지에 대한 반려동물의 확률이 더 높음을 유추할 수 있습니다. 하지만 n-gram 방식의 언어모델은 단어간의 유사도를 구할 수 없기 때문에, 이와 같이 훈련 corpus에서 보지 못한 단어(unseen word sequence)의 조합(n-gram)에 대해서 효과적으로 대처할 수 없습니다.
하지만 Neural Network LM은 word embedding을 사용하여 단어를 벡터화(vectorize) 함으로써, 강아지와 고양이를 비슷한 vector로 학습하고, 자동차와 고양이 보다 훨씬 높은 유사도를 가지게 합니다. 따라서 NNLM이 훈련 corpus에서 보지 못한 단어의 조합을 보더라도, 비슷한 훈련 데이터로부터 배운 것과 유사하게 대처할 수 있습니다.
Neural Network LM은 많은 형태를 가질 수 있지만 우리는 가장 효율적이고 흔한 형태인 Recurrent Neural Network(RNN)의 일종인 Long Short Term Memory(LSTM)을 활용한 방식에 대해서 짚고 넘어가도록 하겠습니다.
Recurrent Neural Network LM
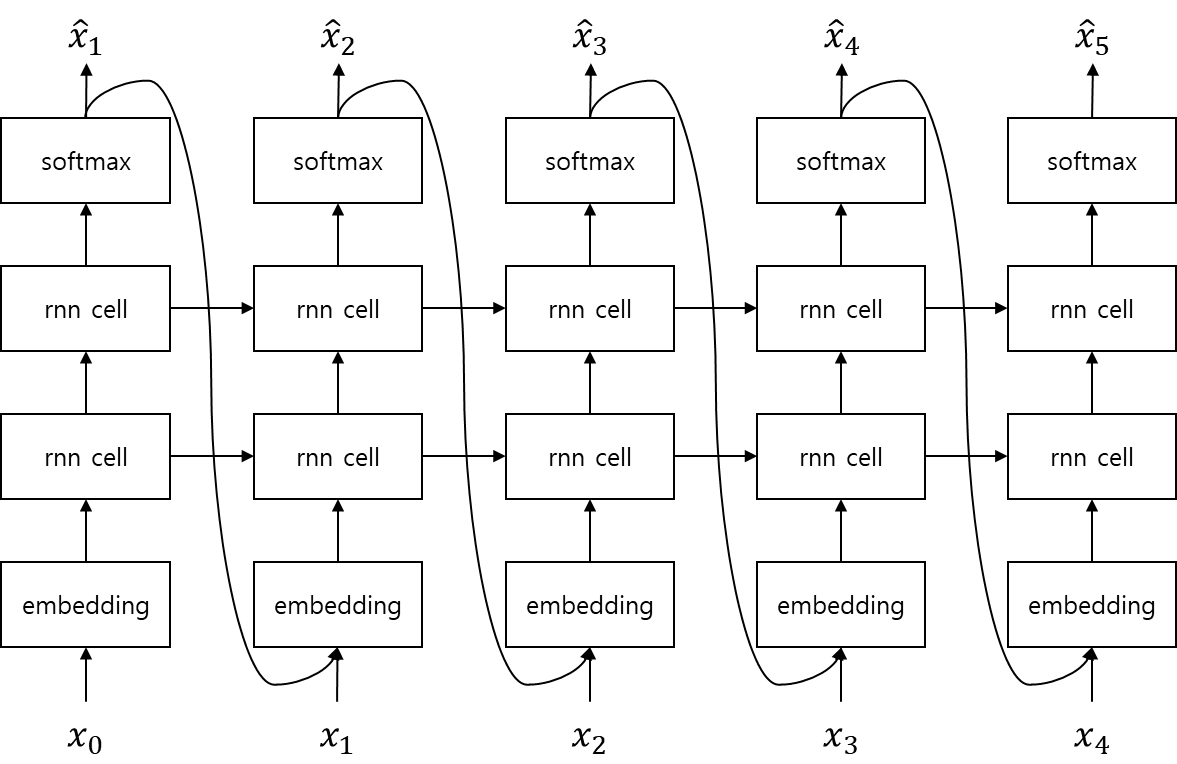
Recurrent Neural Network Lauguage Model (RNNLM)은 위와 같은 구조를 지니고 있습니다. 기존의 언어모델은 각각의 단어를 descrete한 존재로써 처리하였기 때문에, 문장(word sequence)의 길이가 길어지면 희소성(sparseness)문제가 발생하여 어려운 부분이 있었습니다. 따라서, 이전까지의 단어만 (주로 ) 조건부로 잡아 확률을 근사(approximation) 하였습니다. 하지만, RNN LM은 단어를 embedding하여 벡터화(vectorize)함으로써, 희소성 문제를 해소하였기 때문에, 문장의 첫 단어부터 모두 조건부에 넣어 확률을 근사 할 수 있습니다.
로그를 취하여 표현 해보면 아래와 같습니다.
Implementation
이제 RNN을 활용한 언어모델을 구현 해 보도록 하겠습니다. PyTorch로 구현하기에 앞서, 이를 수식화 해보면 아래와 같습니다. -- language_model.py 가 이를 구현 한 코드 입니다.
위의 수식을 따라가 보면, 문장 를 입력으로 받아 각 time-step 별()로 Emb(embedding layer)에 넣어 정해진 차원(dimension)의 embedding vector를 얻습니다. RNN은 해당 embedding vector를 입력으로 받아, hidden size의 vector 형태로 반환 합니다. 이 RNN 출력 vector를 linear layer를 통해 어휘(vocabulary)수 dimension의 vector로 변환 한 후, softmax를 취하여 을 구합니다.
여기서 우리는 LSTM을 사용하여 RNN을 대체 할 것이고, LSTM은 여러 층(layer)로 구성되어 있으며, 각 층 사이에는 dropout이 들어가 있습니다. 이 결과()를 이전 섹션에서 perplexity와 엔트로피(entropy)와의 관계를 설명하였듯이, cross entropy loss를 사용하여 모델() 최적화를 수행 합니다.
Code
아래의 PyTorch 코드는 저자의 github에서 다운로드 할 수 있습니다. (업데이트 여부에 따라 코드가 약간 달라질 수 있습니다.)
- github repo url: https://github.com/kh-kim/OpenNLMTK
language_model.py
import torch
import torch.nn as nn
class LanguageModel(nn.Module):
def __init__(self, vocab_size, word_vec_dim = 512,
hidden_size = 512,
n_layers = 4,
dropout_p = .2,
max_length = 255
):
self.vocab_size = vocab_size
self.word_vec_dim = word_vec_dim
self.hidden_size = hidden_size
self.n_layers = n_layers
self.dropout_p = dropout_p
self.max_length = max_length
super(LanguageModel, self).__init__()
self.emb = nn.Embedding(vocab_size, word_vec_dim, padding_idx = 0)
self.rnn = nn.LSTM(word_vec_dim, hidden_size, n_layers, batch_first = True, dropout = dropout_p)
self.out = nn.Linear(hidden_size, vocab_size, bias = True)
self.log_softmax = nn.LogSoftmax(dim = 2)
def forward(self, x):
# |x| = (batch_size, length)
x = self.emb(x)
# |x| = (batch_size, length, word_vec_dim)
x, (h, c) = self.rnn(x)
# |x| = (batch_size, length, hidden_size)
x = self.out(x)
# |x| = (batch_size, length, vocab_size)
y_hat = self.log_softmax(x)
return y_hat
data_loader.py
from torchtext import data, datasets
BOS = 2
EOS = 3
class DataLoader():
def __init__(self, train_fn, valid_fn, batch_size = 64,
device = -1,
max_vocab = 99999999,
max_length = 255,
fix_length = None,
use_bos = True,
use_eos = True,
shuffle = True
):
super(DataLoader, self).__init__()
self.text = data.Field(sequential = True,
use_vocab = True,
batch_first = True,
include_lengths = True,
fix_length = fix_length,
init_token = '<BOS>' if use_bos else None,
eos_token = '<EOS>' if use_eos else None
)
train = LanguageModelDataset(path = train_fn,
fields = [('text', self.text)],
max_length = max_length
)
valid = LanguageModelDataset(path = valid_fn,
fields = [('text', self.text)],
max_length = max_length
)
self.train_iter = data.BucketIterator(train,
batch_size = batch_size,
device = device,
shuffle = shuffle,
sort_key=lambda x: -len(x.text),
sort_within_batch = True
)
self.valid_iter = data.BucketIterator(valid,
batch_size = batch_size,
device = device,
shuffle = False,
sort_key=lambda x: -len(x.text),
sort_within_batch = True
)
self.text.build_vocab(train, max_size = max_vocab)
class LanguageModelDataset(data.Dataset):
"""Defines a dataset for machine translation."""
def __init__(self, path, fields, max_length=None, **kwargs):
if not isinstance(fields[0], (tuple, list)):
fields = [('text', fields[0])]
examples = []
with open(path) as f:
for line in f:
line = line.strip()
if max_length and max_length < len(line.split()):
continue
if line != '':
examples.append(data.Example.fromlist(
[line], fields))
super(LanguageModelDataset, self).__init__(examples, fields, **kwargs)
if __name__ == '__main__':
import sys
loader = DataLoader(sys.argv[1], sys.argv[2])
for batch_index, batch in enumerate(loader.train_iter):
print(batch.text)
if batch_index > 1:
break
trainer.py
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.utils as torch_utils
import utils
def get_loss(y, y_hat, criterion, do_backward = True):
batch_size = y.size(0)
loss = criterion(y_hat.contiguous().view(-1, y_hat.size(-1)), y.contiguous().view(-1))
if do_backward:
# since size_average parameter is off, we need to devide it by batch size before back-prop.
loss.div(batch_size).backward()
return loss
def train_epoch(model, criterion, train_iter, valid_iter, config):
current_lr = config.lr
lowest_valid_loss = np.inf
no_improve_cnt = 0
for epoch in range(1, config.n_epochs):
optimizer = optim.SGD(model.parameters(), lr = current_lr)
print("current learning rate: %f" % current_lr)
print(optimizer)
sample_cnt = 0
total_loss, total_word_count, total_parameter_norm, total_grad_norm = 0, 0, 0, 0
start_time = time.time()
train_loss = np.inf
for batch_index, batch in enumerate(train_iter):
optimizer.zero_grad()
current_batch_word_cnt = torch.sum(batch.text[1])
# Most important lines in this method.
# Since model takes BOS + sentence as an input and sentence + EOS as an output,
# x(input) excludes last index, and y(index) excludes first index.
x = batch.text[0][:, :-1]
y = batch.text[0][:, 1:]
# feed-forward
y_hat = model(x)
# calcuate loss and gradients with back-propagation
loss = get_loss(y, y_hat, criterion)
# simple math to show stats
total_loss += float(loss)
total_word_count += int(current_batch_word_cnt)
total_parameter_norm += float(utils.get_parameter_norm(model.parameters()))
total_grad_norm += float(utils.get_grad_norm(model.parameters()))
if (batch_index + 1) % config.print_every == 0:
avg_loss = total_loss / total_word_count
avg_parameter_norm = total_parameter_norm / config.print_every
avg_grad_norm = total_grad_norm / config.print_every
elapsed_time = time.time() - start_time
print("epoch: %d batch: %d/%d\t|param|: %.2f\t|g_param|: %.2f\tloss: %.4f\tPPL: %.2f\t%5d words/s %3d secs" % (epoch,
batch_index + 1,
int((len(train_iter.dataset.examples) // config.batch_size) * config.iter_ratio_in_epoch),
avg_parameter_norm,
avg_grad_norm,
avg_loss,
np.exp(avg_loss),
total_word_count // elapsed_time,
elapsed_time
))
total_loss, total_word_count, total_parameter_norm, total_grad_norm = 0, 0, 0, 0
start_time = time.time()
train_loss = avg_loss
# Another important line in this method.
# In orther to avoid gradient exploding, we apply gradient clipping.
torch_utils.clip_grad_norm_(model.parameters(), config.max_grad_norm)
# Take a step of gradient descent.
optimizer.step()
sample_cnt += batch.text[0].size(0)
if sample_cnt >= len(train_iter.dataset.examples) * config.iter_ratio_in_epoch:
break
sample_cnt = 0
total_loss, total_word_count = 0, 0
model.eval()
for batch_index, batch in enumerate(valid_iter):
current_batch_word_cnt = torch.sum(batch.text[1])
x = batch.text[0][:, :-1]
y = batch.text[0][:, 1:]
y_hat = model(x)
loss = get_loss(y, y_hat, criterion, do_backward = False)
total_loss += float(loss)
total_word_count += int(current_batch_word_cnt)
sample_cnt += batch.text[0].size(0)
if sample_cnt >= len(valid_iter.dataset.examples):
break
avg_loss = total_loss / total_word_count
print("valid loss: %.4f\tPPL: %.2f" % (avg_loss, np.exp(avg_loss)))
if lowest_valid_loss > avg_loss:
lowest_valid_loss = avg_loss
no_improve_cnt = 0
else:
# decrease learing rate if there is no improvement.
current_lr /= 10.
no_improve_cnt += 1
model.train()
model_fn = config.model.split(".")
model_fn = model_fn[:-1] + ["%02d" % epoch, "%.2f-%.2f" % (train_loss, np.exp(train_loss)), "%.2f-%.2f" % (avg_loss, np.exp(avg_loss))] + [model_fn[-1]]
# PyTorch provides efficient method for save and load model, which uses python pickle.
torch.save({"model": model.state_dict(),
"config": config,
"epoch": epoch + 1,
"current_lr": current_lr
}, ".".join(model_fn))
if config.early_stop > 0 and no_improve_cnt > config.early_stop:
break
utils.py
import torch
def get_grad_norm(parameters, norm_type = 2):
parameters = list(filter(lambda p: p.grad is not None, parameters))
total_norm = 0
try:
for p in parameters:
param_norm = p.grad.data.norm(norm_type)
total_norm += param_norm ** norm_type
total_norm = total_norm ** (1. / norm_type)
except Exception as e:
print(e)
return total_norm
def get_parameter_norm(parameters, norm_type = 2):
total_norm = 0
try:
for p in parameters:
param_norm = p.data.norm(norm_type)
total_norm += param_norm ** norm_type
total_norm = total_norm ** (1. / norm_type)
except Exception as e:
print(e)
return total_norm
train.py
import argparse
import torch
import torch.nn as nn
from data_loader import DataLoader
import data_loader
from language_model import LanguageModel as LM
import trainer
def define_argparser():
p = argparse.ArgumentParser()
p.add_argument('-model', required = True)
p.add_argument('-train', required = True)
p.add_argument('-valid', required = True)
p.add_argument('-gpu_id', type = int, default = -1)
p.add_argument('-batch_size', type = int, default = 64)
p.add_argument('-n_epochs', type = int, default = 20)
p.add_argument('-print_every', type = int, default = 50)
p.add_argument('-early_stop', type = int, default = 3)
p.add_argument('-iter_ratio_in_epoch', type = float, default = 1.)
p.add_argument('-dropout', type = float, default = .1)
p.add_argument('-word_vec_dim', type = int, default = 256)
p.add_argument('-hidden_size', type = int, default = 256)
p.add_argument('-max_length', type = int, default = 80)
p.add_argument('-n_layers', type = int, default = 4)
p.add_argument('-max_grad_norm', type = float, default = 5.)
p.add_argument('-lr', type = float, default = 1.)
p.add_argument('-min_lr', type = float, default = .000001)
config = p.parse_args()
return config
if __name__ == '__main__':
config = define_argparser()
loader = DataLoader(config.train,
config.valid,
batch_size = config.batch_size,
device = config.gpu_id,
max_length = config.max_length
)
model = LM(len(loader.text.vocab),
word_vec_dim = config.word_vec_dim,
hidden_size = config.hidden_size,
n_layers = config.n_layers,
dropout_p = config.dropout,
max_length = config.max_length
)
# Let criterion cannot count EOS as right prediction, because EOS is easy to predict.
loss_weight = torch.ones(len(loader.text.vocab))
loss_weight[data_loader.EOS] = 0
criterion = nn.NLLLoss(weight = loss_weight, size_average = False)
print(model)
print(criterion)
trainer.train_epoch(model,
criterion,
loader.train_iter,
loader.valid_iter,
config
)
Conclusion
NNLM은 word embedding vector를 사용하여 희소성(sparseness)을 해결하여 큰 효과를 보았습니다. 따라서 훈련 데이터셋에서 보지 못한 단어(unseen word sequence)의 조합에 대해서도 훌륭한 대처가 가능합니다. 하지만 그만큼 연산량에 있어서 n-gram에 비해서 매우 많은 대가를 치루어야 합니다. 단순히 table look-up 수준의 연산량을 필요로 하는 n-gram방식에 비해서 NNLM은 다수의 matrix 연산등이 포함된 feed forward 연산을 수행해야 하기 때문입니다. 그럼에도 불구하고 GPU의 사용과 점점 빨라지는 H\W 사이에서 NNLM의 중요성은 커지고 있고, 실제로도 많은 분야에 적용되어 훌륭한 성과를 거두고 있습니다.