Machine Translation (MT)
번역은 인류가 언어를 사용하기 시작한 이래로 큰 관심사 중에 하나였습니다. 그러한 의미에서 기계 번역(Machine Translation)은 단순히 언어를 번역하는 것이 아닌, 자연언어처리 영역에서의 종합예술이라 할 수 있습니다. 사실 이번 챕터를 위해서 이전 챕터들을 다루었다고 해도 과언이 아닙니다. Neural Machine Translation (NMT)는 end-to-end learning 으로써, Rule Based Machine Translation (RBMT), Statistical Machine Translation (SMT)로 이어져온 기계 번역의 30년 역사 중에서 가장 큰 성취를 이루어냈습니다. 이번 챕터는 NMT에 대한 인사이트를 얻을 수 있도록, seq2seq with attention의 동작 방식/원리를 이해하고, 더 나아가 응용 방법에 대해서도 소개 합니다. 또한, 기계번역 시스템을 만들기 위한 프로세스와 최신 연구 동향을 아울러 소개 합니다.
Objective
번역의 궁극적인 목표는 어떤 언어(, e.g. french)의 문장이 주어졌을 때, 우리가 원하는 언어(, e.g. english)로 확률을 최대로 하는 문장을 찾아내는 것 입니다.
Why it is so hard?
인간의 언어는 컴퓨터의 언어(e.g. programming language)와 같이 명확하지 않습니다. 우리는 언어의 모호성(ambiguity)을 늘림으로써, 의사소통의 효율을 극대화 시켰습니다. 예를 들어 우리는 정보를 생략하고 말을 짧게 해 버리고, 같은 단어 같은 구절이라고 하더라도 때에 따라 다른 의미로 해석될 수 있습니다. 더욱이 한국어의 경우에는 첫 챕터에서 다루었듯이 어순이 불규칙하고 주어가 생략 되는 등, 더욱 더 난이도가 높아졌습니다. 또한, 언어라는 것은 그 민족의 문화를 담고 있기 때문에, 수천년의 세월동안 쌓여온 사람들의 의식, 철학이 담겨져있고, 그러한 차이들로 하여금 또 다시 번역을 어렵게 만듭니다. 결국, 이러한 점들은 컴퓨터로 하여금 우리의 말을 번역하고자 할 때 큰 장벽으로 다가옵니다.

대표적인 번역 실패 사례
In brightest day, in blackest night,
(일기가 좋은 날, 진흙같은 어두운 밤,)
No evil shall escape my sight.
(아니다 이 악마야, 내 앞에서 사라지지.)
Let those who worship evil's might,
(누가 사악한 수도악마를 숭배하는지 볼까,)
Beware my power, Green Lantern's light!!!
(나의 능력을 조심해라, 그린 랜턴 빛!)
Why it is so important?
하지만 이러한 어려움에도 불구하고 기계 번역은 우리에게 꼭 필요한 과제입니다. 이 순간에도 전세계에서는 기계번역을 통해서 많은 일들이 일어납니다. Facebook과 같은 세계인이 소통하는 SNS, Amazon과 같은 전 세계를 대상으로 하는 인터넷 쇼핑몰에서도 번역 서비스를 제공하며 사용자들은 이를 통해 편리함을 얻을 수 있습니다.
History
Rule based Machine Translation
전통적인 방식의 번역이라고 할 수 있습니다. 우리가 흔히 어릴때 부터 배워 온 방식입니다. 문장의 구조를 분석하고, 그 분석에 따라 규칙을 세우고 분류를 나누어서 정해진 규칙에 따라서 번역을 합니다. 밑에서 다룰 SMT에 비해서 자연스러운 표현이 가능하지만, 그 규칙을 일일히 사람이 만들어내야 하므로 번역기를 만드는데 많은 자원과 시간이 소모됩니다. 따라서 번역 언어쌍을 확장할 때에도, 매번 새로운 규칙을 찾아내고 적용해야 하기 때문에 굉장히 불리합니다.
Statistical Machine Translation
NMT이전에 세상을 지배하던 번역 방식입니다. 대량의 양방향 corpus로부터 통계를 얻어내어 번역 시스템을 구성합니다. Google이 자신의 번역 시스템에 도입하면서 더욱 유명해졌습니다. 이 시스템 또한 여러가지 모듈로 이루어져 굉장히 복잡합니다. 통계기반 방식을 사용하므로 언어쌍을 확장할 때, 대부분의 알고리즘이나 시스템은 유지되므로 기존의 RBMT에 비하여 매우 유리하였습니다.
Neural Machine Translation
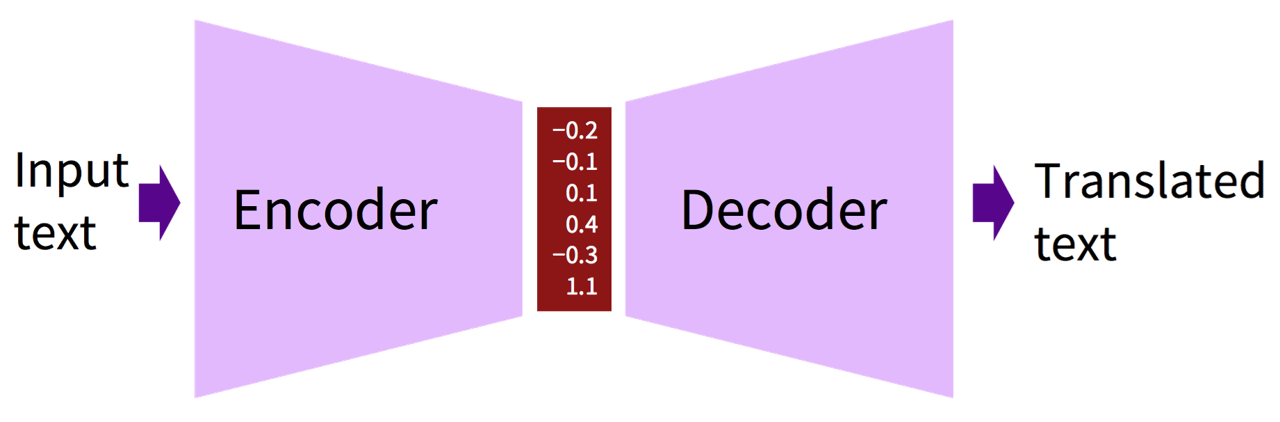
사실, 딥러닝 이전의 AI의 전성기(1980년대)에도 Neural Network을 사용하여 Machine Translation 문제를 해결하려는 시도는 여럿 있었습니다. 하지만 당시에도 형태의 구조를 가지고 있었지만, 당연히 지금과 같은 성능을 내기는 어려웠습니다.
Invasion of NMT
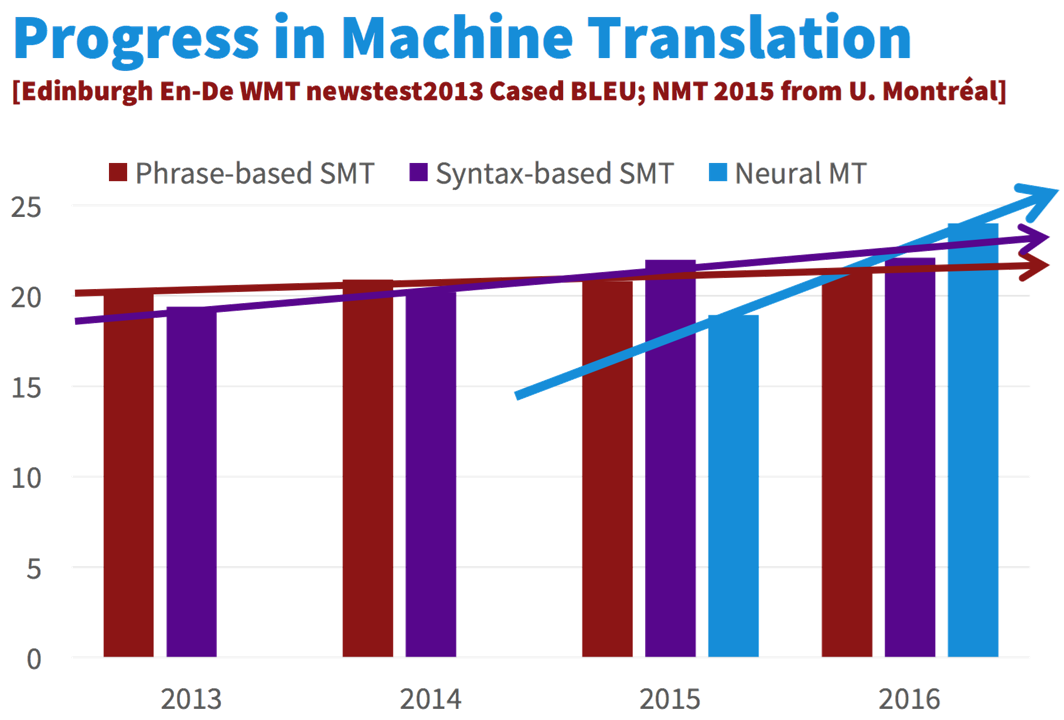
현재의 NMT 방식이 제안되고, 곧 기존의 SMT 방식을 크게 앞질러 버렸습니다. 이제는 구글의 번역기에도 NMT 방식이 사용됩니다.
Why it works well?
왜 Neural Machine Translation이 잘 동작하는 것일까요?
- End-to-end Model
- NMT 이전의 SMT의 경우에는 번역시스템이 여러가지 모듈로 구성이 되어 있었고, 이로 하여금 시스템의 복잡도를 증가시켜 훈련에 있어서 훨씬 지금보다 어려운 경향이 있었습니다. 하지만 NMT는 단 하나의 모델로 번역을 해결함으로써, 성능을 극대화 하였습니다.
- Better language model
- 신경망 언어모델(Neural Network Language Model)을 기반으로 하는 구조이므로 기존의 SMT방식의 언어모델보다 더 강합니다. 따라서 희소성(sparseness)문제가 해결 되었으며, 자연스러운 번역 결과 문장을 생성함에 있어서 더 강점을 나타냅니다.
- Great context embedding
- Neural Network의 특기를 십분 발휘하여 문장의 의미를 벡터화(vectorize)하는 능력이 뛰어납니다. 따라서, 노이즈나 희소성(sparseness)에도 훨씬 더 잘 대처할 수 있게 되었습니다.